Que: What are the ways to intercept a ASP page?
Ans: We can use IHttpModule, IHTTPHandler and IHttpAsyncHandler(for asynch).
Que: What is better a HTTPModule or Global.asax?
Ans: HTTPModule has advantage of getting used by different application, but Global,asax is limited to single app only.But in Global.asax we get advantage of different other events available like Session_Start, Session_End.
Que: What is difference between HTTPHandler and HTTPModule?
Ans:
HTTP handlers
HTTP handlers are the end point objects in ASP.NET pipeline and an HTTP Handler essentially processes the request and produces the response. For example an ASP.NET Page is an HTTP Handler.HTTP handlers are the .NET components that implement the System.Web.IHttpHandler interface. Any class that implements the IHttpHandler interface can act as a target for the incoming HTTP requests.
HTTP Modules
HTTP Modules are objects which also participate the pipeline but they work before and after the HTTP Handler does its job, and produce additional services within the pipeline (for example associating session within a request before HTTP handler executes, and saving the session state after HTTP handler has done its job, is basically done by an HTTP module, SessionStateModule).HTTP modules are .NET components that implement the System.Web.IHttpModule interface. These components plug themselves into the ASP.NET request processing pipeline by registering themselves for certain events. Whenever those events occur, ASP.NET invokes the interested HTTP modules so that the modules can play with the request.
Que: How can we intercept every url request inside a WPF webbrowser?
Ans: There are events available like BeforeNavigate2(inside IWebBrowser2 interface), which can be used to do that.
Saturday, December 25, 2010
Saturday, December 11, 2010
XMLHttpRequest
Que: What is XMLHTTPRequest object?
Ans: XMLHttpRequest is an API available in web browser scripting language to make Ajax calls. It sends HTTP or HTTPS requests to web server and load server response. It is very important in web development technique.
Que: How to use XMLHTTPRequest in your script?
Ans: Here is code snippet which creates an XMLHTTPRequest:
if (type of XMLHttpRequest == "undefined")
XMLHttpRequest = function () {
try { return new ActiveXObject("Msxml2.XMLHTTP.6.0"); }
catch (e) {}
try { return new ActiveXObject("Msxml2.XMLHTTP.3.0"); }
catch (e) {}
throw new Error("This browser does not support XMLHttpRequest.");
};
var xmlhttp = new XMLHttpRequest();
xmlhttp.open("GET","http://www.abc.com",true);
xmlhttp.onreadystatechange = checkData;
xmlhttp.send(null);
function checkData()
{
//Response received.
}
Que: What all different methods associated with XMLHTTPRequest object?
Ans:
-Open (“method”, “URL”, “asynchronous”, “username”, “pswd”)
method: HTTP request method to be used( GET,POST,HEAD,PUT,DELETE,OPTIONS)
URL: URL of HTTP request.
asynchronous: Call will be asynch or synch.
-username and pswd(optional): authentication and authorization.
-Send(args): Sends a request to the server resource.args can be anything which could be converted into string. if args is a DOM document object, a user agent should assure the document is turned into well-formed XML using the encoding indicated by the inputEncoding property of the document object.
-Onreadystatechange: is an event handler, which fires at every state(loading,loaded,completed etc.) change.
-Ready State: current state of the object.
0 = uninitialized
1 = loading(open method has been invoked successfully)
2 = loaded(send method has been invoked and the HTTP response headers have been received)
3 = interactive(HTTP response content begins to load)
4 = complete(HTTP response content has finished loading)
-getAllResponseHeaders(): Returns a collection of HTTP headers as string.
Que: what is synchronous and asynchronous request?
Ans: An asynch request ("true") will not wait on a server response before continuing on with the execution of the current script. It will instead invoke the onreadystatechange event listener of the XMLHttpRequest object throughout the various stages of the request. A synch request ("false") however will block execution of the current script until the request has been completed, thus not invoking the onreadystatechange event listener.
Que: What is difference between open and send method. Do we really need both to make a request?
Ans: open method only initializes the request but we need to use send() method to actually send that request to server side.
Que: How can we check whether URL is valid or not?
Ans: We can make use of readystate to check the response:
xmlhttp.open("HEAD", "http://www.abc.com",true);
xmlhttp.onreadystatechange=function() {
if (xmlhttp.readyState==4) {
if (xmlhttp.status==200) alert("Got it right ")
else if (xmlhttp.status==404) alert("URL doesn't exist!")
else alert("Status got is: "+xmlhttp.status)
}
}
xmlhttp.send(null)
Que: How can we make a request to get only header?
Ans: here is code snippet to do so:
xmlhttp.open("HEAD", "http://www.abc.com",true);
xmlhttp.onreadystatechange=function() {
if (xmlhttp.readyState==4) {
alert(xmlhttp.getAllResponseHeaders())
}
}
xmlhttp.send(null);
If you want a specific header value, you can use getResponseHeader (“header name”);
Ans: XMLHttpRequest is an API available in web browser scripting language to make Ajax calls. It sends HTTP or HTTPS requests to web server and load server response. It is very important in web development technique.
Que: How to use XMLHTTPRequest in your script?
Ans: Here is code snippet which creates an XMLHTTPRequest:
if (type of XMLHttpRequest == "undefined")
XMLHttpRequest = function () {
try { return new ActiveXObject("Msxml2.XMLHTTP.6.0"); }
catch (e) {}
try { return new ActiveXObject("Msxml2.XMLHTTP.3.0"); }
catch (e) {}
throw new Error("This browser does not support XMLHttpRequest.");
};
var xmlhttp = new XMLHttpRequest();
xmlhttp.open("GET","http://www.abc.com",true);
xmlhttp.onreadystatechange = checkData;
xmlhttp.send(null);
function checkData()
{
//Response received.
}
Que: What all different methods associated with XMLHTTPRequest object?
Ans:
-Open (“method”, “URL”, “asynchronous”, “username”, “pswd”)
method: HTTP request method to be used( GET,POST,HEAD,PUT,DELETE,OPTIONS)
URL: URL of HTTP request.
asynchronous: Call will be asynch or synch.
-username and pswd(optional): authentication and authorization.
-Send(args): Sends a request to the server resource.args can be anything which could be converted into string. if args is a DOM document object, a user agent should assure the document is turned into well-formed XML using the encoding indicated by the inputEncoding property of the document object.
-Onreadystatechange: is an event handler, which fires at every state(loading,loaded,completed etc.) change.
-Ready State: current state of the object.
0 = uninitialized
1 = loading(open method has been invoked successfully)
2 = loaded(send method has been invoked and the HTTP response headers have been received)
3 = interactive(HTTP response content begins to load)
4 = complete(HTTP response content has finished loading)
-getAllResponseHeaders(): Returns a collection of HTTP headers as string.
Que: what is synchronous and asynchronous request?
Ans: An asynch request ("true") will not wait on a server response before continuing on with the execution of the current script. It will instead invoke the onreadystatechange event listener of the XMLHttpRequest object throughout the various stages of the request. A synch request ("false") however will block execution of the current script until the request has been completed, thus not invoking the onreadystatechange event listener.
Que: What is difference between open and send method. Do we really need both to make a request?
Ans: open method only initializes the request but we need to use send() method to actually send that request to server side.
Que: How can we check whether URL is valid or not?
Ans: We can make use of readystate to check the response:
xmlhttp.open("HEAD", "http://www.abc.com",true);
xmlhttp.onreadystatechange=function() {
if (xmlhttp.readyState==4) {
if (xmlhttp.status==200) alert("Got it right ")
else if (xmlhttp.status==404) alert("URL doesn't exist!")
else alert("Status got is: "+xmlhttp.status)
}
}
xmlhttp.send(null)
Que: How can we make a request to get only header?
Ans: here is code snippet to do so:
xmlhttp.open("HEAD", "http://www.abc.com",true);
xmlhttp.onreadystatechange=function() {
if (xmlhttp.readyState==4) {
alert(xmlhttp.getAllResponseHeaders())
}
}
xmlhttp.send(null);
If you want a specific header value, you can use getResponseHeader (“header name”);
Sunday, November 28, 2010
.NET Fundamentals 13(AppDomain)
Que: What is AppDomain?
Ans: AppDomain is logical container for set of assemblies.It is kind of shell to make appliction secure. It is different from a process. A process can have multiple AppDomains. It is kind of isolation of memory used by application. As the memory in appdomain is managed by CLR, so it is responsibility of CLR to make sure that one appdomain doesn't access the memory of other appdomain.
Que: What is difference between AppDomain and a process?
Ans: A process is OS level concept whereas AppDomain is .NET level concept. The purpose of both is to provide security but at different level. An AppDomain can belong to only one process, but a process can have more than one AppDomain in it.
Que: What is the advantage of having AppDomain?
Ans: We are having concept of process to provide isolation of memory, but still .NET have given AppDomains, because creating a process is always costly. AppDomain creation is .NET level so creating an AppDomain is not so costly. Moreover unloading an AppDomain causes unloading all the assemblies loaded inside that AppDomain.and unloading one appdomain never affects another appdomain.
Que. If AppDomain is isolating the memory usage, than is it possible to access object in one AppDomain in another AppDomain?
Ans:It is possible that code in one appdomain can communicate with types and objects in another appdomain.
Object by reference:
If an object have to get shared by reference, that class has to inherit from "MarshalByRefObject" class.
Actually when an object is passed as reference from one appdomain to another, then CLR create a proxy object at destination. This proxy looks exactly same as type of object we want pass, but it has information about how to access that object in another appdomain(where original object got created).So the actually one appdomain still not accessing the memory of another appdomain. but CLR manages this by itself. Now when we try to use that object(by executing some method in it) through proxy, actually Appdomain transition occures and we reaches to original object(and executes the method).
Object by Value:
if we want to pass an object by value from on appdomain to another we need to add [Serializable] attribute to that class. So ih this case all field values of original object gets copied to destination appdomain. So if we unload the appdomain still the object exist in destination appdomain. Actually CLR creates exact replica of original object in destination.
Que: How to unload an appdomain?
Ans:Appdomain has a static unload method which will unload the appdomain.All threads running in appdomain and also those thread which can return at some point , get unloaded. CLR forces all the threads involve with unloading appdomain to throw ThreadAbortException. During shutdown no new threads are allowed to enter the application domain and all application domain specific data structures are freed. You cannot unload an application domain in a finalizer or destructor. If the application domain has run code from a domain-neutral assembly, the domains copy of the statics and related CLR data structures are freed, but the code for the domain-neutral assembly remains until the process is shutdown. There is no mechanism to fully unload a domain-neutral assembly other than shutting down the process.
Note:
Application domain is not a secure boundary when the application runs with full trust. Applications running with full trust can execute native code and circumvent all security checks by the .NET runtime. ASP.NET applications run with full trust by default.
Ans: AppDomain is logical container for set of assemblies.It is kind of shell to make appliction secure. It is different from a process. A process can have multiple AppDomains. It is kind of isolation of memory used by application. As the memory in appdomain is managed by CLR, so it is responsibility of CLR to make sure that one appdomain doesn't access the memory of other appdomain.
Que: What is difference between AppDomain and a process?
Ans: A process is OS level concept whereas AppDomain is .NET level concept. The purpose of both is to provide security but at different level. An AppDomain can belong to only one process, but a process can have more than one AppDomain in it.
Que: What is the advantage of having AppDomain?
Ans: We are having concept of process to provide isolation of memory, but still .NET have given AppDomains, because creating a process is always costly. AppDomain creation is .NET level so creating an AppDomain is not so costly. Moreover unloading an AppDomain causes unloading all the assemblies loaded inside that AppDomain.and unloading one appdomain never affects another appdomain.
Que. If AppDomain is isolating the memory usage, than is it possible to access object in one AppDomain in another AppDomain?
Ans:It is possible that code in one appdomain can communicate with types and objects in another appdomain.
Object by reference:
If an object have to get shared by reference, that class has to inherit from "MarshalByRefObject" class.
Actually when an object is passed as reference from one appdomain to another, then CLR create a proxy object at destination. This proxy looks exactly same as type of object we want pass, but it has information about how to access that object in another appdomain(where original object got created).So the actually one appdomain still not accessing the memory of another appdomain. but CLR manages this by itself. Now when we try to use that object(by executing some method in it) through proxy, actually Appdomain transition occures and we reaches to original object(and executes the method).
Object by Value:
if we want to pass an object by value from on appdomain to another we need to add [Serializable] attribute to that class. So ih this case all field values of original object gets copied to destination appdomain. So if we unload the appdomain still the object exist in destination appdomain. Actually CLR creates exact replica of original object in destination.
Que: How to unload an appdomain?
Ans:Appdomain has a static unload method which will unload the appdomain.All threads running in appdomain and also those thread which can return at some point , get unloaded. CLR forces all the threads involve with unloading appdomain to throw ThreadAbortException. During shutdown no new threads are allowed to enter the application domain and all application domain specific data structures are freed. You cannot unload an application domain in a finalizer or destructor. If the application domain has run code from a domain-neutral assembly, the domains copy of the statics and related CLR data structures are freed, but the code for the domain-neutral assembly remains until the process is shutdown. There is no mechanism to fully unload a domain-neutral assembly other than shutting down the process.
Note:
Application domain is not a secure boundary when the application runs with full trust. Applications running with full trust can execute native code and circumvent all security checks by the .NET runtime. ASP.NET applications run with full trust by default.
Saturday, November 20, 2010
Java Part-1
Que1: What is difference between Process and Thread?
Ans: Process and threads are methods to get parallel execution of an application. A process have its own address space, where multiple thread can execute, It means a process can have multiple threads in it. Multiple process can interact with each others only by Inter process communication mechanism thus Inter process communication is always expensive but inter thread communication is cheap. As two process uses separate memory spaces thus if one process dies it never affects other process, but if one thread gets corrupt then other thread(and sometimes corresponding process) will get die.
Que2: What are abstract classes?
Ans: Class that contains one or more methods which are only declared not defined.In other words Abstract class is class which have one or more abstract methods(Method without body). We can not have any object of abstract class.But it can be sub classed, and that subclass have to implement all abstract methods else this subclass too have to declare as abstract class. Abstract class can be used to refer an object reference, so that at run time we can decide which method of subclass to execute.
Que3: What is an interface?
Ans: Interface is an abstract class with all abstract methods. Interface is generally defined to show a contract that any class implementing this interface will implement methods in it.
Note: Syntax for both abstract class and interface is different. The definition given it only for understanding.
Que4: What is the difference abstract class and interface?
Ans: In Abstract class contains one or many abstract methods but an interface have only abstract methods. A class can be a subclass of only one abstract class, but a class can implement one or many interfaces. Interface is a way to achieve multiple inheritance.
Que5: What is overriding?
Ans: When method name and its parameters (signature) are same in sub and super class but its definition is different. it is called as overriding.
Que6: What is overloading?
Ans: Method with same name and different signature in same class, is called method overloading.
Que7: What are different ways to block a thread in Java?
Ans: There are 3 ways:
Sleep(): thread will be blocked for specific amount of time.
Suspend(): thread need to use resume() to return back.
wait(): thread need to use notify() to return back.
Que8: What is JAR file?
Ans: JAR file is a kind of zip file for Java application containing application or libraries in the form of classes and associated meta data and resources.
Que9: What is the difference between "==" and .equals() method?
Ans: "==" compares object reference only but .equals compares its fields. Generally to compare any 2 objects use .equals method not "==".
Que10: What is the difference between constructor and methods?
Ans: Constructor has same name as class name, no other method can have name as class name. Constructor has no return type, not even void. constructor may or may not be explicitly defined for any class, Java does provide a default constructor.
For example,
public class abc{
int i;
public static void main(String args[])
{
abc h1 = new abc();
System.out.println("this works");
}
}
This works.
But if we gave abc h1=new abc(5); then it gives error that constructor not specified.
Ans: Process and threads are methods to get parallel execution of an application. A process have its own address space, where multiple thread can execute, It means a process can have multiple threads in it. Multiple process can interact with each others only by Inter process communication mechanism thus Inter process communication is always expensive but inter thread communication is cheap. As two process uses separate memory spaces thus if one process dies it never affects other process, but if one thread gets corrupt then other thread(and sometimes corresponding process) will get die.
Que2: What are abstract classes?
Ans: Class that contains one or more methods which are only declared not defined.In other words Abstract class is class which have one or more abstract methods(Method without body). We can not have any object of abstract class.But it can be sub classed, and that subclass have to implement all abstract methods else this subclass too have to declare as abstract class. Abstract class can be used to refer an object reference, so that at run time we can decide which method of subclass to execute.
Que3: What is an interface?
Ans: Interface is an abstract class with all abstract methods. Interface is generally defined to show a contract that any class implementing this interface will implement methods in it.
Note: Syntax for both abstract class and interface is different. The definition given it only for understanding.
Que4: What is the difference abstract class and interface?
Ans: In Abstract class contains one or many abstract methods but an interface have only abstract methods. A class can be a subclass of only one abstract class, but a class can implement one or many interfaces. Interface is a way to achieve multiple inheritance.
Que5: What is overriding?
Ans: When method name and its parameters (signature) are same in sub and super class but its definition is different. it is called as overriding.
Que6: What is overloading?
Ans: Method with same name and different signature in same class, is called method overloading.
Que7: What are different ways to block a thread in Java?
Ans: There are 3 ways:
Sleep(): thread will be blocked for specific amount of time.
Suspend(): thread need to use resume() to return back.
wait(): thread need to use notify() to return back.
Que8: What is JAR file?
Ans: JAR file is a kind of zip file for Java application containing application or libraries in the form of classes and associated meta data and resources.
Que9: What is the difference between "==" and .equals() method?
Ans: "==" compares object reference only but .equals compares its fields. Generally to compare any 2 objects use .equals method not "==".
Que10: What is the difference between constructor and methods?
Ans: Constructor has same name as class name, no other method can have name as class name. Constructor has no return type, not even void. constructor may or may not be explicitly defined for any class, Java does provide a default constructor.
For example,
public class abc{
int i;
public static void main(String args[])
{
abc h1 = new abc();
System.out.println("this works");
}
}
This works.
But if we gave abc h1=new abc(5); then it gives error that constructor not specified.
Saturday, October 16, 2010
Process Vs Threads
Both threads and processes are methods of parallelizing an application. However, processes are independent execution units that contain their own state information, use their own address spaces, and only interact with each other via interprocess communication mechanisms (generally managed by the operating system).Thread is a design construct that doesn't affect the architecture of an application. A single process can have multiple threads; all threads within a process share the same state and same memory space, and can communicate with each other directly, because they share the same variables.
 T1 and T2 are threads inside one process.Process is unit of allocation of resources but the threads are unit of execution.Inter process communication is always expensive. it needs context switch, whereas
T1 and T2 are threads inside one process.Process is unit of allocation of resources but the threads are unit of execution.Inter process communication is always expensive. it needs context switch, whereas
inter thread communication is cheap, it can use process memory and may not need to context switch. The process are secure as one process is dead, other process wont get affected, but if one thread get corrupt and die ,other threads and even corresponding process will get die.
inter thread communication is cheap, it can use process memory and may not need to context switch. The process are secure as one process is dead, other process wont get affected, but if one thread get corrupt and die ,other threads and even corresponding process will get die.
Sunday, October 10, 2010
.NET Fundamentals 12 (ASP page Error handler)
ASP.NET provides several levels at which you can handle and respond to errors that may occur when you run an ASP.NET application. ASP.NET provides three main methods that allow you to trap and respond to errors when they occur: Page_Error, Application_Error, and the application configuration file (Web.config).
Page_Error:
The Page_Error event handler provides a way to trap errors that occur at the page level. You can simply display error information or you can log the event or perform some other action.
void Page_Load(object sender, System.EventArgs e)
{
throw(new Exception());
}
public void Page_Error(object sender,EventArgs e)
{
Exception objErr = Server.GetLastError().GetBaseException();
Server.ClearError();
}
Server.ClearError prevents the error from continuing to the Application_Error event handler.
Application_Error:
The Application_Error event handler is specified in the Global.asax file of application. It means other pages in same virtual directory can also use the same error handler.
void Page_Load(object sender, System.EventArgs e)
{
throw(new Exception());
}
//In Global.asax
protected void Application_Error(object sender, EventArgs e)
{
Exception objErr = Server.GetLastError().GetBaseException();
Server.ClearError();
}
Note:
1) In both of the above methods AutoEventWireup in aspx page should be true. It is ASP attribute which wires up certain event handlers (like Page_Load, Page_Error etc) to the page.If this attribute is set to false then none of these events will fire. These event handler have fixed name which can't be changed.
2) The error details can be found in Server.GetLastError().GetBaseException().
Web.Config method:
If you do not call Server.ClearError or trap the error in the Page_Error or Application_Error event handler, the error is handled based on the settings in the section of the Web.config file. In the section, you can specify a redirect page as a default error page (defaultRedirect) or specify to a particular page based on the HTTP error code that is raised. You can use this method to customize the error message that the user receives.
mode = On
DefaultRedirect = Page where you want to redirect on error.
Inside customeErrors tag you have en error tag in which you can specify different page for different errors.The error tag looks like this:
error statusCode="404" redirect="filenotfound.htm"
Status code is error code and the redirect will be the page where w want to redirect.
In customErrors we can select mode attribute. It hase 3 values to set:
-> On: Unhandled exceptions redirect the user to the specified defaultRedirect page. This mode is used mainly in production.
-> Off: Users receive the exception information and are not redirected to the defaultRedirect page. This mode is used mainly in development.
-> RemoteOnly: Only users who access the site on the local computer (by using localhost) receive the exception information. All other users are redirected to the defaultRedirect page. This mode is used mainly for debugging.
Here is one more attribute which needs to be set to achive desired purpose, that is redirecmode.
It is an optional property. It has 2 values which can be set depending upon requirement.
ResponseRedirect: Specifies that the URL to direct the browser to must be different from the original Web request URL.In this case the server will completely redirect your application page to error page. All the content of application page will not be available anymore.
ResponseRewrite: Specifies that the URL to direct the browser to must be the original Web request URL.In simple words in this case the url which you see in webbrowser will be the application url only, but the http content will be of error page.Here server rewrite the html content of your application page.
The different among 2 can be seen on refresh of page. In 1st case error page will get refresh. but in 2nd Case your application will again try to reload and if again some error occurs then we will get error page again.
ApplicationInstanceError method:
Wen can use this method in following way:
HttpContext.Current.ApplicationInstance.Error += new EventHandler(ApplicationInstance_Error).
by this we can attach error handler in our application. it is equivalent to response.rewrite method in customeError tag mentioned above. If we have both Application_Error(In Global.asax) as well as ApplicationInstanceError handler then Application_Error will be called 1st and then the other one.
The benefit we get by this is, Response.ReWrite doesn't work for application in different virtual directory, but by this method we get all the benefit of response.rewrite and whoever application uses this Dll having ApplicationInstanceError handler will be able to invoke it.
Page_Error:
The Page_Error event handler provides a way to trap errors that occur at the page level. You can simply display error information or you can log the event or perform some other action.
void Page_Load(object sender, System.EventArgs e)
{
throw(new Exception());
}
public void Page_Error(object sender,EventArgs e)
{
Exception objErr = Server.GetLastError().GetBaseException();
Server.ClearError();
}
Server.ClearError prevents the error from continuing to the Application_Error event handler.
Application_Error:
The Application_Error event handler is specified in the Global.asax file of application. It means other pages in same virtual directory can also use the same error handler.
void Page_Load(object sender, System.EventArgs e)
{
throw(new Exception());
}
//In Global.asax
protected void Application_Error(object sender, EventArgs e)
{
Exception objErr = Server.GetLastError().GetBaseException();
Server.ClearError();
}
Note:
1) In both of the above methods AutoEventWireup in aspx page should be true. It is ASP attribute which wires up certain event handlers (like Page_Load, Page_Error etc) to the page.If this attribute is set to false then none of these events will fire. These event handler have fixed name which can't be changed.
2) The error details can be found in Server.GetLastError().GetBaseException().
Web.Config method:
If you do not call Server.ClearError or trap the error in the Page_Error or Application_Error event handler, the error is handled based on the settings in the
-> Off: Users receive the exception information and are not redirected to the defaultRedirect page. This mode is used mainly in development.
-> RemoteOnly: Only users who access the site on the local computer (by using localhost) receive the exception information. All other users are redirected to the defaultRedirect page. This mode is used mainly for debugging.
ResponseRewrite: Specifies that the URL to direct the browser to must be the original Web request URL.In simple words in this case the url which you see in webbrowser will be the application url only, but the http content will be of error page.Here server rewrite the html content of your application page.
The different among 2 can be seen on refresh of page. In 1st case error page will get refresh. but in 2nd Case your application will again try to reload and if again some error occurs then we will get error page again.
Sunday, October 3, 2010
.Net Fundamentals 11(Generics)
Why Generics-
Type safety ,better performance,Source code protection and Cleaner code
(Type safty and performance are discussed later)
Source code protection: Developers don't need any source code if they are using generic algorithms.
Cleaner Code: as compiler take care of type safety so we need not to type caste the things again and again. so we get a good readable code.
Better performance - Only in case of value type, as it avoid boxing and unboxing.
Type Safety-
static void Main(string[] args)
{
ArrayList list = new ArrayList();
populateList(list);
int temp;
for (int i = 0; i < list.Count; i++)
{
temp = (int)list[i];
Console.WriteLine(temp);
}
}
private static void populateList(ArrayList list)
{
list.Add(1);
list.Add(2);
list.Add("hello"); //No error from compiler
}It will cause runtime error -> Specified cast is not valid
But in case of generics:
List<int> list = new List <int>();
list.Add(1);
list.Add(2);
list.Add("hello"); //Compiler shows error
So at compile time itself we get error in case of type mismatch.
Boxing/UnBoxing-
Boxing is the act of converting a value type to a reference type. If we look at line #2 of the first code sample above, we’re putting an Int32 (a value type) into an ArrayList which stores everything as System.Object (a reference type).
Boxing causes memory allocation on managed heap, which causes more frequent garbage collections, which in turn hurt an application performance.
Unboxing is the act of converting a reference type to a value type (e.g., if we were taking an item out of the ArrayList and having to cast: int num = (int)list[0];).
- Generic Type and inheritance
IList<string> mylist = new List<string>();
IList<int> myintlist = new List<int>();
Both of these types will be derived from whatever type the generic type was derived from. If the generic List<T> is derived from object, it means list<string> and List<int> are also derived from object.
It does not mean that mylist.GetType()==myintlist.GetType() will return you true.
Inheritance in Generics -
There are different kind of inheritance possible -
 Points to remember -
Points to remember -
In case of (ii) and (iv) all overridden methods will have to define the types in the generic implementation. In other words we can not have any generic class definition which has overridden method and the return type or input parameters are T.
Here is the example -
class A<T> : C
{
T temp;
public A(T t) { temp = t; }
public override string GetT(string t) { return "";}
public void SetT(T t) { temp = t;}
}
class C
{
public C() { }
public virtual String GetT(string a ) { return "C";}
}
In above case we can not have method GetT taking parameter as T or returning type T.
Generic Interface -
Using generic we can define interface that defines methods with generic parameters. Here is the example -
Here is nonGeneric IComparable interface
public class A : IComparable
{
public int myInt = 0;
public int CompareTo(object obj)
{
A a = obj as A;
return this.myInt.CompareTo(a.myInt);
}
}
Here is Generic Comparable interface.
public class B : IComparable<B>
{
public int bint = 0;
public int CompareTo(B other)
{
return this.bint.CompareTo(other.bint);
}
}
If we compare above 2 examples then we see in 2nd case, we dont need any type cast.
Constraints -
While compiling generic code, c# compiler make sure that the code will work for anytype exist today, or introduced later. For example -
private void Min<T>(T o1)
{
Console.WriteLine(o1.ToString());
}
The above code compiles successfully but
private void Min<T>(T o1)
{
Console.WriteLine(o1.CompareTo(o1));
}
Won't compile. As every type will have ToString method available to them, but not every type will have compareTo Method available. Thus CLR provides "constraints" to solve this limitation. We can always define this method like this-
private void Min<T>(T o1) where T: IComparable<T>
{
Console.WriteLine(o1.CompareTo(o1));
}
It not possible to put a constraint on overridden method, when there is not constraint available on parent method. Here is the example-
class A<T>
{
public A() { }
public virtual void Min<T>(T o1)
{
Console.WriteLine(o1.ToString());
}
}
class B<T> : A<T>
{
public B() { }
public override void Min<T>(T o1) where T:ICloneable
{
Console.WriteLine(o1.ToString());
}
}
The above code will give error, because Min MEthod doesn't have any constraint in base class, but we are trying to put a constraint in derived class.
Moreover we can not put constraint using object class, which means following code won't compile-
public override void Min<T>(T o1) where T:object
{
Console.WriteLine(o1.ToString());
}
But its always possible to put constraints of value type or reference type using class/struct as constraints.
Here are some description about different kind of constraints allowed in c# -
Constraint : Description
where T : struct With a struct constraint, type T must be a value type.
where T : class The class constraint indicates that type T must be a reference type.
where T : IMyInterface where T : IMyInterface specifies that type T is required to implement interface IMyInterface.
where T : MyClass where T : MyClass specifies that type T is required to derive from base class MyClass.
where T : new() where T : new() is a constructor constraint and specifies that type T must have a default constructor.
where T1 : T2 With constraints it is also possible to specify that type T1 derives from a generic type T2. This constraint is known as naked type constraint.
Code Explosion-
When we use a generic type and specify the type arguments, CLR defines new type object for every type we mention. For example -
IList<string> mylist = new List<string>();
IList<int> myintlist = new List<int>();
For above 2 line, CLR will create 2 different types, list of string and list of int. It means for every method/type combincation CLR will generate native code, which is called as code explosion. This might hurt the performance. In order to overcome this issue, CLR has its own optimization -
Optimization 1 - If one method is called for specific argument then CLR will compile it once and will serve all the instances of this method call from same code generated(in a appdomain).
Optimization 2- CLR compiles the code for reference type only once, as all reference types are just pointers, so List of string and list of Datetime will share the same compiled code.(This is not applicable for Value types)
Setting a Default Value-
If we want to set a default value of any generic type then we need to use "default" keyword, We can not directly assign null, as value type don't have null.
Which means following code will give error -
private static setDefault<T>(T o1)
{
T temp = null; //error
}
To fix the above code use default-
private static setDefault<T>(T o1)
{
T temp = default(T);
}
temp will be null if its ref type and will be all bits zero if its a value type.
Comparison of generic type-
private static CompareResult<T>(T o1, T o2)
{
if(o1 == o2) // error
}
Above code will give error as not every value type has == operator.
Open and closed types-
Type with the generic type parameters(no definition of T) is called open type and CLR does not allow an instance of any open type. If actual data type are passed for all type arguments, it is called as closed type.
Ex:
Object o;
Open type :
Type t = typeof(Dictionary<,>);
o = createinstance(t); //error
Closed Type:
//DictionaryString is defined like this Dictionary an open type.
//here we have also defined 2nd parameter so it has became a closed type
Type t = typeof(DictionaryString<GUID>);
o = createInstance(t); //No Error
Static Member-
If a static constructor is defined on generic type, then it will be execute once for every close type.
For example -
There is class which contains static filed x -
public class StaticDemo < T >
{
public static int x;
}
Because of using the class StaticDemo <T> both with a string type and an int type, two sets of static fields exist:
StaticDemo<string>.x = 4;
StaticDemo<int>.x = 5;
Console.WriteLine(StaticDemo<string>.x); // writes 4
Limitations-
Methamatical operators like +, -, * and /, can not be applied on any generic type, because we dont know the type beforehand. Which means its impossible to write methematical algo that works on arbitrary data type.
Type safety ,better performance,Source code protection and Cleaner code
(Type safty and performance are discussed later)
Source code protection: Developers don't need any source code if they are using generic algorithms.
Cleaner Code: as compiler take care of type safety so we need not to type caste the things again and again. so we get a good readable code.
Better performance - Only in case of value type, as it avoid boxing and unboxing.
Type Safety-
static void Main(string[] args)
{
ArrayList list = new ArrayList();
populateList(list);
int temp;
for (int i = 0; i < list.Count; i++)
{
temp = (int)list[i];
Console.WriteLine(temp);
}
}
private static void populateList(ArrayList list)
{
list.Add(1);
list.Add(2);
list.Add("hello"); //No error from compiler
}It will cause runtime error -> Specified cast is not valid
But in case of generics:
List<int>
list.Add(1);
list.Add(2);
list.Add("hello"); //Compiler shows error
So at compile time itself we get error in case of type mismatch.
Boxing/UnBoxing-
Boxing is the act of converting a value type to a reference type. If we look at line #2 of the first code sample above, we’re putting an Int32 (a value type) into an ArrayList which stores everything as System.Object (a reference type).
Boxing causes memory allocation on managed heap, which causes more frequent garbage collections, which in turn hurt an application performance.
Unboxing is the act of converting a reference type to a value type (e.g., if we were taking an item out of the ArrayList and having to cast: int num = (int)list[0];).
- Generic Type and inheritance
IList<string> mylist = new List<string>();
IList<int> myintlist = new List<int>();
Both of these types will be derived from whatever type the generic type was derived from. If the generic List<T> is derived from object, it means list<string> and List<int> are also derived from object.
It does not mean that mylist.GetType()==myintlist.GetType() will return you true.
Inheritance in Generics -
There are different kind of inheritance possible -

In case of (ii) and (iv) all overridden methods will have to define the types in the generic implementation. In other words we can not have any generic class definition which has overridden method and the return type or input parameters are T.
Here is the example -
class A<T> : C
{
T temp;
public A(T t) { temp = t; }
public override string GetT(string t) { return "";}
public void SetT(T t) { temp = t;}
}
class C
{
public C() { }
public virtual String GetT(string a ) { return "C";}
}
In above case we can not have method GetT taking parameter as T or returning type T.
Generic Interface -
Using generic we can define interface that defines methods with generic parameters. Here is the example -
Here is nonGeneric IComparable interface
public class A : IComparable
{
public int myInt = 0;
public int CompareTo(object obj)
{
A a = obj as A;
return this.myInt.CompareTo(a.myInt);
}
}
Here is Generic Comparable interface.
public class B : IComparable<B>
{
public int bint = 0;
public int CompareTo(B other)
{
return this.bint.CompareTo(other.bint);
}
}
If we compare above 2 examples then we see in 2nd case, we dont need any type cast.
Constraints -
While compiling generic code, c# compiler make sure that the code will work for anytype exist today, or introduced later. For example -
private void Min<T>(T o1)
{
Console.WriteLine(o1.ToString());
}
The above code compiles successfully but
private void Min<T>(T o1)
{
Console.WriteLine(o1.CompareTo(o1));
}
Won't compile. As every type will have ToString method available to them, but not every type will have compareTo Method available. Thus CLR provides "constraints" to solve this limitation. We can always define this method like this-
private void Min<T>(T o1) where T: IComparable<T>
{
Console.WriteLine(o1.CompareTo(o1));
}
It not possible to put a constraint on overridden method, when there is not constraint available on parent method. Here is the example-
class A<T>
{
public A() { }
public virtual void Min<T>(T o1)
{
Console.WriteLine(o1.ToString());
}
}
class B<T> : A<T>
{
public B() { }
public override void Min<T>(T o1) where T:ICloneable
{
Console.WriteLine(o1.ToString());
}
}
The above code will give error, because Min MEthod doesn't have any constraint in base class, but we are trying to put a constraint in derived class.
Moreover we can not put constraint using object class, which means following code won't compile-
public override void Min<T>(T o1) where T:object
{
Console.WriteLine(o1.ToString());
}
But its always possible to put constraints of value type or reference type using class/struct as constraints.
Here are some description about different kind of constraints allowed in c# -
Constraint : Description
where T : struct With a struct constraint, type T must be a value type.
where T : class The class constraint indicates that type T must be a reference type.
where T : IMyInterface where T : IMyInterface specifies that type T is required to implement interface IMyInterface.
where T : MyClass where T : MyClass specifies that type T is required to derive from base class MyClass.
where T : new() where T : new() is a constructor constraint and specifies that type T must have a default constructor.
where T1 : T2 With constraints it is also possible to specify that type T1 derives from a generic type T2. This constraint is known as naked type constraint.
Code Explosion-
When we use a generic type and specify the type arguments, CLR defines new type object for every type we mention. For example -
IList<string> mylist = new List<string>();
IList<int> myintlist = new List<int>();
For above 2 line, CLR will create 2 different types, list of string and list of int. It means for every method/type combincation CLR will generate native code, which is called as code explosion. This might hurt the performance. In order to overcome this issue, CLR has its own optimization -
Optimization 1 - If one method is called for specific argument then CLR will compile it once and will serve all the instances of this method call from same code generated(in a appdomain).
Optimization 2- CLR compiles the code for reference type only once, as all reference types are just pointers, so List of string and list of Datetime will share the same compiled code.(This is not applicable for Value types)
Setting a Default Value-
If we want to set a default value of any generic type then we need to use "default" keyword, We can not directly assign null, as value type don't have null.
Which means following code will give error -
private static setDefault<T>(T o1)
{
T temp = null; //error
}
To fix the above code use default-
private static setDefault<T>(T o1)
{
T temp = default(T);
}
temp will be null if its ref type and will be all bits zero if its a value type.
Comparison of generic type-
private static CompareResult<T>(T o1, T o2)
{
if(o1 == o2) // error
}
Above code will give error as not every value type has == operator.
Open and closed types-
Type with the generic type parameters(no definition of T) is called open type and CLR does not allow an instance of any open type. If actual data type are passed for all type arguments, it is called as closed type.
Ex:
Object o;
Open type :
Type t = typeof(Dictionary<,>);
o = createinstance(t); //error
Closed Type:
//DictionaryString is defined like this Dictionary an open type.
//here we have also defined 2nd parameter so it has became a closed type
Type t = typeof(DictionaryString<GUID>);
o = createInstance(t); //No Error
Static Member-
If a static constructor is defined on generic type, then it will be execute once for every close type.
For example -
There is class which contains static filed x -
public class StaticDemo < T >
{
public static int x;
}
Because of using the class StaticDemo <T> both with a string type and an int type, two sets of static fields exist:
StaticDemo<string>.x = 4;
StaticDemo<int>.x = 5;
Console.WriteLine(StaticDemo<string>.x); // writes 4
Limitations-
Methamatical operators like +, -, * and /, can not be applied on any generic type, because we dont know the type beforehand. Which means its impossible to write methematical algo that works on arbitrary data type.
Saturday, October 2, 2010
.Net Fundamentals 10(Marshalling/UnMarshalling)
What is Marshalling/UnMarshalling and type of marshalling in .net?
Marshalling is as process of making an object avail across network or application domain. Marshaling is the act of taking data from the environment you are in and exporting it to another environment.
UnMarshalling creates an object from the marshaled data.
There are 2 ways of Marshalling:
Blittable : A type is considered blittable if it has a common representation in managed and unmanaged code memory. Non-blittable types require custom marshaling to convert between the unmanaged and managed representations.
[InAttribute] and [OutAttribute]
These are called as directional attributes because the control marshalling direction.
[InAttribute] tells the CLR to marshal data from the caller to callee at the begining of the call, while [OutAttribute] tells the CLR to marshal data from the caller to callee upon return. Caller and callee can be either unmanaged or managed code.(Ex. In a P/Invoke call managed code calls unmanaged code, but in reverse P/Invoke unmanaged code calls managed code through function pointer.)
Why can't I serialize .NET Framework classes like exceptions and fonts?
The XmlSerializer is primarily designed with two goals in mind: XML data binding to XSD compliant data structures and operation without any special code access privileges. These two goals work against the XmlSerializer as a general-purpose object persistence solution for some kinds of objects.
General purpose serialization may require accessing private fields, by-passing the framework's standard object construction process, and so on, which in turn requires special privileges. The SoapFormatter from the System.Runtime.Serialization.Formatters.Soap namespace provides an alternative that is not subject to these restrictions, but requires full trust to operate. It also produces an XML format, a generation of which is customizable using the attributes in the System.Runtime.Remoting.Metadata namespace.
How do I serialize collections of objects?
The XmlSerializer throws an exception when the collection contains types that were not declared to the constructor of the XmlSerializer. You can:
->Declare the types to the serializer by passing in a Type[] with the types to expect within the collection.
OR
->Implement a strongly-typed collection derived from System.Collections.CollectionBase with an indexer matching the Add() method.
Why can't I serialize hashtables?
The XmlSerializer cannot process classes implementing the IDictionary interface. This was partly due to schedule constraints and partly due to the fact that a hashtable does not have a counterpart in the XSD type system. The only solution is to implement a custom hashtable that does not implement the IDictionary interface.
Why do exceptions thrown by the XmlSerializer not contain any details about the error?
They do contain all the information, but it's stored in the InnerException property of the exception thrown, which is usually an InvalidOperationException. In general, one should always call ToString() on caught exceptions to get the full details of the exception.
Generic delegates:
As we do event-based programming or implement publish-subscribe pattern, we use the delegate feature from .NET heavily. The code below shows how we can use delegate:
public delegate void MydDelegate(int oldValue, int newValue);
class TestClass
{
public MydDelegate OnDataChanged = null;
private int _mydata = 0;
public int MyData
{
get { return _mydata; }
set { UpdateData(value); }
}
private void UpdateData(int updatedData)
{
if (OnDataChanged != null)
{
OnDataChanged(_data, updatedData);
}
_data = updatedData;
}
}
We can then create an instance of TestClass ,and hook up the event handler to its public delegate as shown below.
class Program
{
static void Main(string[] args)
{
TestClass obj = new TestClass();
obj.OnDataChanged += OnDataChanged;
obj.Data = 5;
}
static void OnDataChanged(int oldValue, int newValue)
{
Console.WriteLine("Data changes from " + oldValue + " to " + newValue);
}
}
C# 3.0 or .NET 3.5 has new feature that provides us a set of generic delegates with the name "Action" or "Func", the difference between them is Action does not have return type (void), while Func has return type (refer to MSDN documentation). So from example above we can remove following code:
public delegate void DataChangedDelegate(int oldValue, int newValue);
and replace following code:
public DataChangedDelegate OnDataChanged = null;
with:
public Action OnDataChanged = null;
If the delegate returns bool data type for example, then we can use Func function such as:
public Func OnDataChanged = null;
Marshalling is as process of making an object avail across network or application domain. Marshaling is the act of taking data from the environment you are in and exporting it to another environment.
UnMarshalling creates an object from the marshaled data.
There are 2 ways of Marshalling:
Marshal by Value: In this, the object is serialized into the channel, and a copy of the object is created on the other side of the network. The object to marshal is stored into a stream, and the stream is used to build a copy of the object on the other side with the unmarshalling sequence.Value types are marshalled to unmanaged code on the stack.
Marshal by Reference: Here it creates a proxy on the client that is used to communicate with the remote object. The marshaling sequence of a remote object creates an ObjRef instance that itself can be serialized across the network. Objects that are derived from “MarshalByRefObject” are always marshaled by reference. To marshal a remote object the static method RemotingServices.Marshal () is used. Reference types are passed by address. This means a pointer is passed on the stack, and the pointer contains the address of the marshaled data on the heap. When parameters are passed by reference, a pointer to the parameters on the managed heap is passed to the unmanaged code. Since the unmanaged code receives a pointer, it is possible for the method to modify the data held on the managed heap.Blittable : A type is considered blittable if it has a common representation in managed and unmanaged code memory. Non-blittable types require custom marshaling to convert between the unmanaged and managed representations.
[InAttribute] and [OutAttribute]
These are called as directional attributes because the control marshalling direction.
[InAttribute] tells the CLR to marshal data from the caller to callee at the begining of the call, while [OutAttribute] tells the CLR to marshal data from the caller to callee upon return. Caller and callee can be either unmanaged or managed code.(Ex. In a P/Invoke call managed code calls unmanaged code, but in reverse P/Invoke unmanaged code calls managed code through function pointer.)
Why can't I serialize .NET Framework classes like exceptions and fonts?
The XmlSerializer is primarily designed with two goals in mind: XML data binding to XSD compliant data structures and operation without any special code access privileges. These two goals work against the XmlSerializer as a general-purpose object persistence solution for some kinds of objects.
General purpose serialization may require accessing private fields, by-passing the framework's standard object construction process, and so on, which in turn requires special privileges. The SoapFormatter from the System.Runtime.Serialization.Formatters.Soap namespace provides an alternative that is not subject to these restrictions, but requires full trust to operate. It also produces an XML format, a generation of which is customizable using the attributes in the System.Runtime.Remoting.Metadata namespace.
How do I serialize collections of objects?
The XmlSerializer throws an exception when the collection contains types that were not declared to the constructor of the XmlSerializer. You can:
->Declare the types to the serializer by passing in a Type[] with the types to expect within the collection.
OR
->Implement a strongly-typed collection derived from System.Collections.CollectionBase with an indexer matching the Add() method.
Why can't I serialize hashtables?
The XmlSerializer cannot process classes implementing the IDictionary interface. This was partly due to schedule constraints and partly due to the fact that a hashtable does not have a counterpart in the XSD type system. The only solution is to implement a custom hashtable that does not implement the IDictionary interface.
Why do exceptions thrown by the XmlSerializer not contain any details about the error?
They do contain all the information, but it's stored in the InnerException property of the exception thrown, which is usually an InvalidOperationException. In general, one should always call ToString() on caught exceptions to get the full details of the exception.
Generic delegates:
As we do event-based programming or implement publish-subscribe pattern, we use the delegate feature from .NET heavily. The code below shows how we can use delegate:
public delegate void MydDelegate(int oldValue, int newValue);
class TestClass
{
public MydDelegate OnDataChanged = null;
private int _mydata = 0;
public int MyData
{
get { return _mydata; }
set { UpdateData(value); }
}
private void UpdateData(int updatedData)
{
if (OnDataChanged != null)
{
OnDataChanged(_data, updatedData);
}
_data = updatedData;
}
}
We can then create an instance of TestClass ,and hook up the event handler to its public delegate as shown below.
class Program
{
static void Main(string[] args)
{
TestClass obj = new TestClass();
obj.OnDataChanged += OnDataChanged;
obj.Data = 5;
}
static void OnDataChanged(int oldValue, int newValue)
{
Console.WriteLine("Data changes from " + oldValue + " to " + newValue);
}
}
C# 3.0 or .NET 3.5 has new feature that provides us a set of generic delegates with the name "Action" or "Func", the difference between them is Action does not have return type (void), while Func has return type (refer to MSDN documentation). So from example above we can remove following code:
public delegate void DataChangedDelegate(int oldValue, int newValue);
and replace following code:
public DataChangedDelegate OnDataChanged = null;
with:
public Action
If the delegate returns bool data type for example, then we can use Func function such as:
public Func
Sunday, August 29, 2010
WCF 6(Service Behavior: ConcurrencyMode)
In this post i will try to explain concurrency mode available to configure the WCF service. Concurrency is different from Instance. WCF Instance dictates how objects are created whereas concurrency talks about requests handled by WCF object. Roughly you can say the concurrency is actualy threads available on service side to do your task.
There are three different type of concurrency mode available to configure the service.
1) Single:
A single request has access to the WCF service object and only that request will be processed at a given moment of time. Other requests hav to wait until the request processed by WCF service is not completed.
2) Multiple:
Multiple requests can be handled by the WCF service object by multiple threads at any given moment of time.It gives you a great throughput. But concurrency issue will be there. Its your responsibility to to synchronize your methods.
3) Reentrant:
A single thread has access to WCF service object, but the thread can exit the WCF service to call another WCF service or can also call WCF client through callback. It is almost like Single but a small difference.
In case of single till the callback finishes the service won't allow any other request to get process, but in case of Reentrant it will release the lock and other request will start processing and when callback request comes back it will processed like a new request.
So whenever a call back from other service or from client is required then use reentrant else you may face a deadlock.

Service behavior is combination of instance context mode and concurrency mode. The following table summarizes the service behavior for different combinations:
Instance mode = per Call and Concurrency = Multiple
In this combination multiple instances are created for every call but multiple threads serve every method call to WCF service instance.
 Instance mode = per session and Concurrency = single
Instance mode = per session and Concurrency = single
In this combination one WCF service instance is created for every WCF client session because the WCF instance mode is set to per session. All the method calls are executed in a sequential manner one by one. In other words only one thread is available for all method calls for a particular service instance.
Instance mode = per session and Concurrency = Multiple
In this combination one WCF instance is created for every WCF client session and every method call is run over multiple threads. Below is the pictorial representation of the same.

Instance mode = Single and Concurrency = Single
In this combination only one instance of WCF service instance is created which serves all requests which are sent from all WCF clients. These entire requests are served using only one thread.

Instance mode = Single and Concurrency = Multiple
In this combination one WCF service instance is created for serve all WCF clients. All request are served using multiple / different threads.

Throttling behavior:
WCF throttling settings helps you to put an upper limit on number of concurrent calls, WCF instances and concurrent session. WCF provides 3 ways by which you can define upper limits MaxConcurrentCalls, MaxConcurrentInstances and MaxConcurrentSessions.
MaxConcurrentCalls: - Limits the number of concurrent requests that can be processed by WCF service instances.
MaxConcurrentInstances: - Limits the number of service instances that can be allocated at a given time. When it’s a PerCall services, this value matches the number of concurrent calls. For PerSession services, this value equals the number of active session instances. This setting doesn’t matter for Single instancing mode, because only one instance is ever created.
MaxConcurrentSessions: - Limits the number of active sessions allowed for the service.
There are three different type of concurrency mode available to configure the service.
1) Single:
A single request has access to the WCF service object and only that request will be processed at a given moment of time. Other requests hav to wait until the request processed by WCF service is not completed.
2) Multiple:
Multiple requests can be handled by the WCF service object by multiple threads at any given moment of time.It gives you a great throughput. But concurrency issue will be there. Its your responsibility to to synchronize your methods.
3) Reentrant:
A single thread has access to WCF service object, but the thread can exit the WCF service to call another WCF service or can also call WCF client through callback. It is almost like Single but a small difference.
So whenever a call back from other service or from client is required then use reentrant else you may face a deadlock.

Service behavior is combination of instance context mode and concurrency mode. The following table summarizes the service behavior for different combinations:
Instance Context Mode
|
Concurrency Mode
(Single (Default))
|
Concurrency Mode
(Multiple)
|
Concurrency Mode
(Reentrant)
|
Single
(Single instance for all client)
|
Single thread for all clients
|
Multiple threads for all clients
|
Single threads for all clients, locks are released when calls diverted to other WCF services.
|
PerSession
(Multiple instance per client)
|
Single thread for every client.
|
Multiple threads for every request.
|
Single threads for all clients, locks are released when calls diverted to other WCF services.
|
PerCall (Default)
(Multiple instance for every method call)
|
Single thread for every client
|
Multiple thread for every client
|
Single threads for all clients, locks are released when calls diverted to other WCF services.
|
Instance mode = per Call and Concurrency = Multiple
In this combination multiple instances are created for every call but multiple threads serve every method call to WCF service instance.

In this combination one WCF service instance is created for every WCF client session because the WCF instance mode is set to per session. All the method calls are executed in a sequential manner one by one. In other words only one thread is available for all method calls for a particular service instance.
Instance mode = per session and Concurrency = Multiple
In this combination one WCF instance is created for every WCF client session and every method call is run over multiple threads. Below is the pictorial representation of the same.

Instance mode = Single and Concurrency = Single
In this combination only one instance of WCF service instance is created which serves all requests which are sent from all WCF clients. These entire requests are served using only one thread.

Instance mode = Single and Concurrency = Multiple
In this combination one WCF service instance is created for serve all WCF clients. All request are served using multiple / different threads.
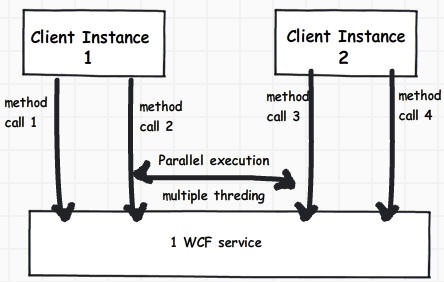
Throttling behavior:
WCF throttling settings helps you to put an upper limit on number of concurrent calls, WCF instances and concurrent session. WCF provides 3 ways by which you can define upper limits MaxConcurrentCalls, MaxConcurrentInstances and MaxConcurrentSessions.
MaxConcurrentCalls: - Limits the number of concurrent requests that can be processed by WCF service instances.
MaxConcurrentInstances: - Limits the number of service instances that can be allocated at a given time. When it’s a PerCall services, this value matches the number of concurrent calls. For PerSession services, this value equals the number of active session instances. This setting doesn’t matter for Single instancing mode, because only one instance is ever created.
MaxConcurrentSessions: - Limits the number of active sessions allowed for the service.
Sunday, July 25, 2010
WCF 5
Problem of Fault on channel:
Once the fault occurs on proxy object, It becomes useless. You can't even call proxy.close() on it, Because of object got faulted. The reason is because of implementation of ICommunicationObject interface. This interface is contract for basic state machine for all communication oriented objects in system. And once the channel is faulted, it goes into fault state. So In order to overcome such problem we need to test state of proxy object and accordingly apply method on it.
If(serviceClient.State == CommunicationState.faulted)
{
..
}
Or we can subscribe to fault event of communication object.
Once the object is faulted we must create a new instance of it.
Auto-Open Vs Open:
WCF support ICommunicationObject which has different states:
Created -> Opening -> Opened -> Closing -> Closed
WCF supports auto-open. This feature allows you to call an I/O method while the object is in the Created (or Opening) state. And objects I/O method ensures that the object transitions to the opened state before calling the inner channel. If you are using a session and you need to send multiple messages concurrently and you care that the first couple messages are actually sent concurrently, you should not use auto-open.
Whenever some method is invoked there is serviceChannel class which does some work and call this
channel.send(message)
Concurrent messages with auto open creates problem,Because it works like this:
If(this.State == created)
{
Open channel
}
So every call has to wait for first call to get finish.Then also there will be race condition for messages to be sent. If the order of message is important then it will create problem. Point to note here is that if we are using multithreading then also the order is not defined.I agree with the same but what if we are using some async calls which must be deterministic.
So in order to avoid it we must open the channel manually by using .open method.
Session limit on server side:
There is always MaxConcurrentSessions on server side. Default value for this is 10. If we are opening channels and crossing the limit of MaxConcurrentSessions, then we can get some timeout errors.
Ex:
for (int i = 0; i < 100; i++)
{
proxy = create channel Using factory
proxy.Mymethod();
((IChannel)proxy).Close();
}
Here if we don't use .close() method and haven't set anything on MaxConcurrentSessions. Then at i=10 it will say time out. and the loop will only be able to create 10 channels.
In order to solve this problem add these statements inside system.servicemodel block inside behaviours tag
behavior name="myBehavior">
serviceThrottling maxConcurrentCalls="Integer" maxConcurrentInstances="Integer" maxConcurrentSessions="Integer" />
/behavior>
And in service tag write this:
service name="mySvc" behaviorConfiguration="myBehavior">
.Close Vs .Abort:
.Close will close the connection gracefully. If there is any call left it will wait for its response and then only it will close the connection.But Abort() is a forced close.
We can understand the difference between these 2 by following code:
try
{
myeClient.CallSomething();
myClient.Close();
}
catch(FaultException)
{
myClient.Abort();
}
Generics class mapping in proxy:
Generics is very common in today world of coding. But WCF does not support use of generics methods for service operation. So open generics type cannot be used for in it. People may think that it is limitation of WCF, But it is not so, Actually it is limitation of WSDL(Used to expose service metadata to consumers).
Then is there no way that we can expose generic object client side?
The answer is Yes!!!!
Service side Code: Service:
[DataContract]
public class MyObj
{
..
}
[ServiceContract]
Public interface IBoundedGenerics
{
[OperationContract]
MyObj GetObj(int id);
}
On client side the proxy get created like this:
[DataContract]
public class MyObjOfint
{
...
}
Resulting Name = Generic Class Name + “of” + Type Parameter + Hash
Hash is there to reduce name collision risk. But causes ugly name. So in order to avoid it we can use
[DataContract(Name = "MyObjOf{0}"]
It will create name of our choice.
Once the fault occurs on proxy object, It becomes useless. You can't even call proxy.close() on it, Because of object got faulted. The reason is because of implementation of ICommunicationObject interface. This interface is contract for basic state machine for all communication oriented objects in system. And once the channel is faulted, it goes into fault state. So In order to overcome such problem we need to test state of proxy object and accordingly apply method on it.
If(serviceClient.State == CommunicationState.faulted)
{
..
}
Or we can subscribe to fault event of communication object.
Once the object is faulted we must create a new instance of it.
Auto-Open Vs Open:
WCF support ICommunicationObject which has different states:
Created -> Opening -> Opened -> Closing -> Closed
WCF supports auto-open. This feature allows you to call an I/O method while the object is in the Created (or Opening) state. And objects I/O method ensures that the object transitions to the opened state before calling the inner channel. If you are using a session and you need to send multiple messages concurrently and you care that the first couple messages are actually sent concurrently, you should not use auto-open.
Whenever some method is invoked there is serviceChannel class which does some work and call this
channel.send(message)
Concurrent messages with auto open creates problem,Because it works like this:
If(this.State == created)
{
Open channel
}
So every call has to wait for first call to get finish.Then also there will be race condition for messages to be sent. If the order of message is important then it will create problem. Point to note here is that if we are using multithreading then also the order is not defined.I agree with the same but what if we are using some async calls which must be deterministic.
So in order to avoid it we must open the channel manually by using .open method.
Session limit on server side:
There is always MaxConcurrentSessions on server side. Default value for this is 10. If we are opening channels and crossing the limit of MaxConcurrentSessions, then we can get some timeout errors.
Ex:
for (int i = 0; i < 100; i++)
{
proxy = create channel Using factory
proxy.Mymethod();
((IChannel)proxy).Close();
}
Here if we don't use .close() method and haven't set anything on MaxConcurrentSessions. Then at i=10 it will say time out. and the loop will only be able to create 10 channels.
In order to solve this problem add these statements inside system.servicemodel block inside behaviours tag
behavior name="myBehavior">
serviceThrottling maxConcurrentCalls="Integer" maxConcurrentInstances="Integer" maxConcurrentSessions="Integer" />
/behavior>
And in service tag write this:
service name="mySvc" behaviorConfiguration="myBehavior">
.Close Vs .Abort:
.Close will close the connection gracefully. If there is any call left it will wait for its response and then only it will close the connection.But Abort() is a forced close.
We can understand the difference between these 2 by following code:
try
{
myeClient.CallSomething();
myClient.Close();
}
catch(FaultException
{
myClient.Abort();
}
Generics is very common in today world of coding. But WCF does not support use of generics methods for service operation. So open generics type cannot be used for in it. People may think that it is limitation of WCF, But it is not so, Actually it is limitation of WSDL(Used to expose service metadata to consumers).
Then is there no way that we can expose generic object client side?
The answer is Yes!!!!
Service side Code: Service:
[DataContract]
public class MyObj
{
..
}
[ServiceContract]
Public interface IBoundedGenerics
{
[OperationContract]
MyObj
}
On client side the proxy get created like this:
[DataContract]
public class MyObjOfint
{
...
}
Resulting Name = Generic Class Name + “of” + Type Parameter + Hash
Hash is there to reduce name collision risk. But causes ugly name. So in order to avoid it we can use
[DataContract(Name = "MyObjOf{0}"]
It will create name of our choice.
WCF 4 (Service Behavior:InstanceContextMode)
Instance management is set of techniques used by WCF to bind a set of messages to a service instance.Instance management is necessary because applications differ in their needs for scalability, performance, throughput, transactions. InstanceContextMode is a property which is available in the System.ServiceModel. InstanceContextMode property is mainly used in the ServiceBehaviour attribute in order to mention what kind of state maintenance your WCF application should provide. There is an enumerator available in the Sytem.ServiceModel library named as InstanceContextMode and it can be used in order to set the property InstanceContextMode.
Per-Call:
Per-call services are the WCF default instantiation mode. When the service type is configured for per-call activation, a service instance, a CLR object, exists only while a client call is in progress. Every client request gets a new dedicated service instance. The benefit with this approach is that the service instance will be caught by client only upto it is being used. So it is possible to dispose service object and expensive resources long before client disposes of the proxy. In order to support per call mode we need to design the service and its contract to support it. Maintaining a state is always a problem with per call mode, because every call creates a new instance of service. So if we want to maintain the session in per call mode also, then on each call we need to fetch the values from som storage( file system, Database) and at end of the call save the values back. But still all the states are not possible to save, For example state containing database connection. Object must reaquire the connection. Per-call activation mode works best when the amount of work to be done in each method call is small and there are no more activities to complete in the background once a method returns. For this reason, you should not spin off background threads or dispatch asynchronous calls back into the instance because the object will be discarded once the method returns. Per-call services clearly offer a trade-off in performance (the overhead of reconstructing the instance state on each method call) with scalability (holding onto the state and the resources it ties in). To use this mode we can explicit add this attribute on service definition.In pre call mode this attribute is optional.
[ServiceBehavior(InstanceContextMode=InstanceContextMode.PerCall)]
We can use basicHTTPBinding with it.

Per-Session:
Windows Communication Foundation can maintain a private session between a client and a particular service instance. When the client creates a new proxy to a service configured as session-aware, the client gets a new dedicated service instance that is independent of all other instances of the same service. That instance will remain in service usually until the client no longer needs it. Each private session uniquely binds a proxy to a particular service instance. Note that the client session has one service instance per proxy. If the client creates another proxy to the same or a different endpoint, that second proxy will be associated with a new instance and session. Because the service instance remains in memory throughout the session, it can maintain state in memory. A service configured for private sessions cannot support large number of clients due to the cost associated with each such dedicated service instance.To support sessions, you need to set Session to true at the contract level:
[ServiceContract(Session = true)]
interface IMyContract {...}
Set the InstanceContextMode property of the ServiceBehavior attribute to InstanceContextMode.PerSession to make teh service to be in per session mode.
[ServiceBehavior(InstanceContextMode = InstanceContextMode.PerSession)]
class MyService : IMyContract {...}
The session will end once the client closes the proxy or the client is idle for some time(timeout( default is 10 mins)).
Any binding but basichttpbinding will work for it.
 Single instance:
Single instance:
When a service is configured as a singleton, all clients get connected to the same single instance independently of each other, regardless of which endpoint of the service they connect to. The singleton service lives forever, and is only disposed of once the host shuts down. The singleton is created exactly once when the host is created. If we are using default constructor, first client will always face time delay in initialization, So to avoid it WCF allows you to create the singleton instance directly using normal CLR instantiation beforehand, initialize the instance, and then open the host with that instance in mind as the singleton service. In singleton as lot many clients are using same service instance so synchronization of methods is always a critical step. We can specify singleton mode by this attribute on service class:
[ServiceBehavior(InstanceContextMode=InstanceContextMode.Single)]
Any binding but basichttpbinding will work for it.

Per-Call:
Per-call services are the WCF default instantiation mode. When the service type is configured for per-call activation, a service instance, a CLR object, exists only while a client call is in progress. Every client request gets a new dedicated service instance. The benefit with this approach is that the service instance will be caught by client only upto it is being used. So it is possible to dispose service object and expensive resources long before client disposes of the proxy. In order to support per call mode we need to design the service and its contract to support it. Maintaining a state is always a problem with per call mode, because every call creates a new instance of service. So if we want to maintain the session in per call mode also, then on each call we need to fetch the values from som storage( file system, Database) and at end of the call save the values back. But still all the states are not possible to save, For example state containing database connection. Object must reaquire the connection. Per-call activation mode works best when the amount of work to be done in each method call is small and there are no more activities to complete in the background once a method returns. For this reason, you should not spin off background threads or dispatch asynchronous calls back into the instance because the object will be discarded once the method returns. Per-call services clearly offer a trade-off in performance (the overhead of reconstructing the instance state on each method call) with scalability (holding onto the state and the resources it ties in). To use this mode we can explicit add this attribute on service definition.In pre call mode this attribute is optional.
[ServiceBehavior(InstanceContextMode=InstanceContextMode.PerCall)]
We can use basicHTTPBinding with it.

Per-Session:
Windows Communication Foundation can maintain a private session between a client and a particular service instance. When the client creates a new proxy to a service configured as session-aware, the client gets a new dedicated service instance that is independent of all other instances of the same service. That instance will remain in service usually until the client no longer needs it. Each private session uniquely binds a proxy to a particular service instance. Note that the client session has one service instance per proxy. If the client creates another proxy to the same or a different endpoint, that second proxy will be associated with a new instance and session. Because the service instance remains in memory throughout the session, it can maintain state in memory. A service configured for private sessions cannot support large number of clients due to the cost associated with each such dedicated service instance.To support sessions, you need to set Session to true at the contract level:
[ServiceContract(Session = true)]
interface IMyContract {...}
Set the InstanceContextMode property of the ServiceBehavior attribute to InstanceContextMode.PerSession to make teh service to be in per session mode.
[ServiceBehavior(InstanceContextMode = InstanceContextMode.PerSession)]
class MyService : IMyContract {...}
The session will end once the client closes the proxy or the client is idle for some time(timeout( default is 10 mins)).
Any binding but basichttpbinding will work for it.

When a service is configured as a singleton, all clients get connected to the same single instance independently of each other, regardless of which endpoint of the service they connect to. The singleton service lives forever, and is only disposed of once the host shuts down. The singleton is created exactly once when the host is created. If we are using default constructor, first client will always face time delay in initialization, So to avoid it WCF allows you to create the singleton instance directly using normal CLR instantiation beforehand, initialize the instance, and then open the host with that instance in mind as the singleton service. In singleton as lot many clients are using same service instance so synchronization of methods is always a critical step. We can specify singleton mode by this attribute on service class:
[ServiceBehavior(InstanceContextMode=InstanceContextMode.Single)]
Any binding but basichttpbinding will work for it.

Saturday, July 3, 2010
.NET fundamentals 8(Assembly concept)
What is an assembly?
* An Assembly is a logical unit of code
* Assembly physically exist as DLLs or EXEs
* One assembly can contain one or more files
* The constituent files can include any file types like image files, text files etc. along with DLLs or EXEs
* When you compile your source code by default the exe/dll generated is actually an assembly
* Unless your code is bundled as assembly it can not be used in any other application
* When you talk about version of a component you are actually talking about version of the assembly to which the component belongs.
* Every assembly file contains information about itself. This information is called as Assembly Manifest.
What is assembly manifest?
* Assembly manifest is a data structure which stores information about an assembly
* This information is stored within the assembly file(DLL/EXE) itself
* The information includes version information, list of constituent files etc.
What is private and shared assembly?
The assembly which is used only by a single application is called as private assembly. Suppose you created a DLL which encapsulates your business logic. This DLL will be used by your client application only and not by any other application. In order to run the application properly your DLL must reside in the same folder in which the client application is installed. Thus the assembly is private to your application.
Suppose that you are creating a general purpose DLL which provides functionality which will be used by variety of applications. Now, instead of each client application having its own copy of DLL you can place the DLL in 'global assembly cache'. Such assemblies are called as shared assemblies.
What is Global Assembly Cache?
Global assembly cache is nothing but a special disk folder where all the shared assemblies will be kept. It is located under:\WinNT\Assembly folder.
How assemblies avoid DLL Hell?
As stated earlier most of the assemblies are private. Hence each client application refers assemblies from its own installation folder. So, even though there are multiple versions of same assembly they will not conflict with each other. Consider following example :
* You created assembly Assembly1
* You also created a client application which uses Assembly1 say Client1
* You installed the client in C:\MyApp1 and also placed Assembly1 in this folder
* After some days you changed Assembly1
* You now created another application Client2 which uses this changed Assembly1
* You installed Client2 in C:\MyApp2 and also placed changed Assembly1 in this folder
* Since both the clients are referring to their own versions of Assembly1 everything goes on smoothly
Now consider the case when you develop assembly that is shared one. In this case it is important to know how assemblies are versioned. All assemblies has a version number in the form:
major.minor.build.revision
If you change the original assembly the changed version will be considered compatible with existing one if the major and minor versions of both the assemblies match.
When the client application requests assembly the requested version number is matched against available versions and the version matching major and minor version numbers and having most latest build and revision number are supplied.
How do I create shared assemblies?
Following steps are involved in creating shared assemblies :
* Create your DLL/EXE source code
* Generate unique assembly name using SN utility
* Sign your DLL/EXE with the private key by modifying AssemblyInfo file
* Compile your DLL/EXE
* Place the resultant DLL/EXE in global assembly cache using AL utility
How do I create unique assembly name?
Microsoft now uses a public-private key pair to uniquely identify an assembly. These keys are generated using a utility called SN.exe (SN stands for shared name). The most common syntax of is :
sn -k mykeyfile.key
Where k represents that we want to generate a key and the file name followed is the file in which the keys will be stored.
How do I sign my DLL/EXE?
Before placing the assembly into shared cache you need to sign it using the keys we just generated. You mention the signing information in a special file called AssemblyInfo. Open the file from VS.NET solution explorer and change it to include following lines :
[assembly:AssemblyKeyFile("file_path")]
Now recompile the project and the assembly will be signed for you.
Note : You can also supply the key file information during command line compilation via /a.keyfile switch.
What makes an assembly unique?
filename + assembly version + culture + public key token
Why publicKeytoken is hash code instead of unique identifier as like GUID, URL?
conserve storage
Is it possible to have reference of unsigned assembly in strongly signed assembly?
No, It will give you compile time error.
How signing make an assembly secure?
Signing has followign steps:
1) When we compile the code compiler will create hash code of IL and every other resource in assembly.
2) Then we sign the assembly. In this this step private Key will encode the has code with some algorithm and will create some kind of identifier and place it in assembly itself.
3) During 2nd step public key corresponding to private key is also placed in assembly.
4) Now when CLR tries to load this assembly, it will again create hash code of assembly and will decode the identifier(placed in 2nd step) with public Key, and will see if both hash codes are same.
If hash codes are different then it means assembly is been tempered and CLR won't load it else it will load it.
What is Satellite assembly?
Satellite assembly is region/location specific resource file. When we want to have our code location specific we can have our data in some resource file. This resource file can be deployed in form of assembly which is nothing but satellite assembly.
Is it possible to have satellite assembly in form of exe not dll?
No, Satellite assembly doesn't contain any code in it, it only contains resources. Thus we can't have Satellite EXE.
What is delay signing?
Delay signing is feature provided by .NET. It is used when we don't want to provide private/public key pair to developer. We want to get it signed in the end i.e. after every kind of testing is done.
There are attributes available which you will need to add in your class:
AssemblyKeyFileAttribute - passes the name of the file containing public key info.
AssemblyDelaySignAttribute - indicates delay sign is used in this assembly.
There are few steps by which we give strong name to assembly so that it can be GACed, and skip validation of our assembly. In this step, assembly only have information about public key.It has strong name but it not validated, thus can be GACed and used.
What is difference between signing an assembly and giving it a strong name?
After signing we get assembly which is completely secure i.e. while loading these assembly CLR will check if it is original one or tempered. But signing is only required to GAC the dll. It is possible to have assembly which has strong name but not signed(delay sign).
* An Assembly is a logical unit of code
* Assembly physically exist as DLLs or EXEs
* One assembly can contain one or more files
* The constituent files can include any file types like image files, text files etc. along with DLLs or EXEs
* When you compile your source code by default the exe/dll generated is actually an assembly
* Unless your code is bundled as assembly it can not be used in any other application
* When you talk about version of a component you are actually talking about version of the assembly to which the component belongs.
* Every assembly file contains information about itself. This information is called as Assembly Manifest.
What is assembly manifest?
* Assembly manifest is a data structure which stores information about an assembly
* This information is stored within the assembly file(DLL/EXE) itself
* The information includes version information, list of constituent files etc.
What is private and shared assembly?
The assembly which is used only by a single application is called as private assembly. Suppose you created a DLL which encapsulates your business logic. This DLL will be used by your client application only and not by any other application. In order to run the application properly your DLL must reside in the same folder in which the client application is installed. Thus the assembly is private to your application.
Suppose that you are creating a general purpose DLL which provides functionality which will be used by variety of applications. Now, instead of each client application having its own copy of DLL you can place the DLL in 'global assembly cache'. Such assemblies are called as shared assemblies.
What is Global Assembly Cache?
Global assembly cache is nothing but a special disk folder where all the shared assemblies will be kept. It is located under
How assemblies avoid DLL Hell?
As stated earlier most of the assemblies are private. Hence each client application refers assemblies from its own installation folder. So, even though there are multiple versions of same assembly they will not conflict with each other. Consider following example :
* You created assembly Assembly1
* You also created a client application which uses Assembly1 say Client1
* You installed the client in C:\MyApp1 and also placed Assembly1 in this folder
* After some days you changed Assembly1
* You now created another application Client2 which uses this changed Assembly1
* You installed Client2 in C:\MyApp2 and also placed changed Assembly1 in this folder
* Since both the clients are referring to their own versions of Assembly1 everything goes on smoothly
Now consider the case when you develop assembly that is shared one. In this case it is important to know how assemblies are versioned. All assemblies has a version number in the form:
major.minor.build.revision
If you change the original assembly the changed version will be considered compatible with existing one if the major and minor versions of both the assemblies match.
When the client application requests assembly the requested version number is matched against available versions and the version matching major and minor version numbers and having most latest build and revision number are supplied.
How do I create shared assemblies?
Following steps are involved in creating shared assemblies :
* Create your DLL/EXE source code
* Generate unique assembly name using SN utility
* Sign your DLL/EXE with the private key by modifying AssemblyInfo file
* Compile your DLL/EXE
* Place the resultant DLL/EXE in global assembly cache using AL utility
How do I create unique assembly name?
Microsoft now uses a public-private key pair to uniquely identify an assembly. These keys are generated using a utility called SN.exe (SN stands for shared name). The most common syntax of is :
sn -k mykeyfile.key
Where k represents that we want to generate a key and the file name followed is the file in which the keys will be stored.
How do I sign my DLL/EXE?
Before placing the assembly into shared cache you need to sign it using the keys we just generated. You mention the signing information in a special file called AssemblyInfo. Open the file from VS.NET solution explorer and change it to include following lines :
[assembly:AssemblyKeyFile("file_path")]
Now recompile the project and the assembly will be signed for you.
Note : You can also supply the key file information during command line compilation via /a.keyfile switch.
What makes an assembly unique?
filename + assembly version + culture + public key token
Why publicKeytoken is hash code instead of unique identifier as like GUID, URL?
conserve storage
Is it possible to have reference of unsigned assembly in strongly signed assembly?
No, It will give you compile time error.
How signing make an assembly secure?
Signing has followign steps:
1) When we compile the code compiler will create hash code of IL and every other resource in assembly.
2) Then we sign the assembly. In this this step private Key will encode the has code with some algorithm and will create some kind of identifier and place it in assembly itself.
3) During 2nd step public key corresponding to private key is also placed in assembly.
4) Now when CLR tries to load this assembly, it will again create hash code of assembly and will decode the identifier(placed in 2nd step) with public Key, and will see if both hash codes are same.
If hash codes are different then it means assembly is been tempered and CLR won't load it else it will load it.
What is Satellite assembly?
Satellite assembly is region/location specific resource file. When we want to have our code location specific we can have our data in some resource file. This resource file can be deployed in form of assembly which is nothing but satellite assembly.
Is it possible to have satellite assembly in form of exe not dll?
No, Satellite assembly doesn't contain any code in it, it only contains resources. Thus we can't have Satellite EXE.
What is delay signing?
Delay signing is feature provided by .NET. It is used when we don't want to provide private/public key pair to developer. We want to get it signed in the end i.e. after every kind of testing is done.
There are attributes available which you will need to add in your class:
AssemblyKeyFileAttribute - passes the name of the file containing public key info.
AssemblyDelaySignAttribute - indicates delay sign is used in this assembly.
There are few steps by which we give strong name to assembly so that it can be GACed, and skip validation of our assembly. In this step, assembly only have information about public key.It has strong name but it not validated, thus can be GACed and used.
What is difference between signing an assembly and giving it a strong name?
.NET fundamentals 7
->What are the types of assemblies?
(A) With Respect to Program Access.
i) Private Assembly- It can be used only in one application.
ii) Public/Shared Assembly- It can be used by all applications in the server.
(B) With Respect to Number of Resources.
i) Static Assembly- It uses fixed resources.
ii) Dynamic Assembly- It supports dynamic creation of resouces or files at runtime programatically.
(C) With Respect to Deployment.
i) Satellite Assembly- Easily Deployable. (Visual Studio 2005).
ii) Resource-Only Assembly- In Visual Studio 2003.
(D) With Respect to Number of Assemblies.
i) Single File Assembly- /Bin/x.dll
ii) Multi File Assembly- /Bin/x.dll
y.dll
z.dll
---
->What are delegates?where are they used ?
A delegate defines a reference type that can be used to encapsulate a method with a specific signature. A delegate instance encapsulates a static or an instance method. Delegates are roughly similar to function pointers in C++; however, delegates are type-safe and secure.
When do you use virutal keyword?
When we need to override a method of the base class in the sub class, then we give the virtual keyword in the base class method. This makes the method in the base class to be overridable. Methods, properties, and indexers can be virtual, which means that their implementation can be overridden in derived classes.
When a virtual method is invoked, the run-time type of the object is checked for an overriding member. The overriding member in the most derived class is called, which might be the original member, if no derived class has overridden the member.
By default, methods are non-virtual. You cannot override a non-virtual method.
You cannot use the virtual modifier with the static, abstract, private or override modifiers.
Virtual properties behave like abstract methods, except for the differences in declaration and invocation syntax. It is an error to use the virtual modifier on a static property.A virtual inherited property can be overridden in a derived class by including a property declaration that uses the override modifier.
What Is Boxing And Unboxing?
Boxing :- Boxing is an implicit conversion of a value type to the type object type
Eg:-
Consider the following declaration of a value-type variable:
int i = 123;
object o = (object) i;
Boxing Conversion
UnBoxing :- Unboxing is an explicit conversion from the type object to a value type
Eg:
int i = 123; // A value type
object box = i; // Boxing
int j = (int)box; // Unboxing
What is Value type and refernce type in .Net?
Value Type : A variable of a value type always contains a value of that type. The assignment to a variable of a value type creates a copy of the assigned value, while the assignment to a variable of a reference type creates a copy of the reference but not of the referenced object.
The value types consist of two main categories:
* Stuct Type
* Enumeration Type
Reference Type :Variables of reference types, referred to as objects, store references to the actual data. This section introduces the following keywords used to declare reference types:
* Class
* Interface
* Delegate
This section also introduces the following built-in reference types:
* object
* string
What is the difference between structures and enumeration?
Unlike classes, structs are value types and do not require heap allocation. A variable of a struct type directly contains the data of the struct, whereas a variable of a class type contains a reference to the data. They are derived from System.ValueType class.
Enum->An enum type is a distinct type that declares a set of named constants.They are strongly typed constants. They are unique types that allow to declare symbolic names to integral values. Enums are value types, which means they contain their own value, can't inherit or be inherited from and assignment copies the value of one enum to another.
public enum Grade
{
A,
B,
C
}
What is namespaces?
Namespace is a logical naming scheme for group related types.Some class types that logically belong together they can be put into a common namespace. They prevent namespace collisions and they provide scoping. They are imported as "using" in C# or "Imports" in Visual Basic. It seems as if these directives specify a particular assembly, but they don't. A namespace can span multiple assemblies, and an assembly can define multiple namespaces. When the compiler needs the definition for a class type, it tracks through each of the different imported namespaces to the type name and searches each referenced assembly until it is found.
Namespaces can be nested. This is very similar to packages in Java as far as scoping is concerned.
What is global assembly cache?
Each computer where the common language runtime is installed has a machine-wide code cache called the global assembly cache. The global assembly cache stores assemblies specifically designated to be shared by several applications on the computer.
There are several ways to deploy an assembly into the global assembly cache:
· Use an installer designed to work with the global assembly cache. This is the preferred option for installing assemblies into the global assembly cache.
· Use a developer tool called the Global Assembly Cache tool (Gacutil.exe), provided by the .NET Framework SDK.
· Use Windows Explorer to drag assemblies into the cache.
What is MSIL?
When compiling to managed code, the compiler translates your source code into Microsoft intermediate language (MSIL), which is a CPU-independent set of instructions that can be efficiently converted to native code. MSIL includes instructions for loading, storing, initializing, and calling methods on objects, as well as instructions for arithmetic and logical operations, control flow, direct memory access, exception handling, and other operations. Before code can be run, MSIL must be converted to CPU-specific code, usually by a just-in-time (JIT) compiler. Because the common language runtime supplies one or more JIT compilers for each computer architecture it supports, the same set of MSIL can be JIT-compiled and run on any supported architecture.
When a compiler produces MSIL, it also produces metadata. Metadata describes the types in your code, including the definition of each type, the signatures of each type's members, the members that your code references, and other data that the runtime uses at execution time. The MSIL and metadata are contained in a portable executable (PE) file that is based on and extends the published Microsoft PE and common object file format (COFF) used historically for executable content. This file format, which accommodates MSIL or native code as well as metadata, enables the operating system to recognize common language runtime images. The presence of metadata in the file along with the MSIL enables your code to describe itself, which means that there is no need for type libraries or Interface Definition Language (IDL). The runtime locates and extracts the metadata from the file as needed during execution.
What is Jit compilers?.how many are available in clr?
Just-In-Time compiler- it converts the language that you write in .Net into machine language that a computer can understand. there are tqo types of JITs one is memory optimized & other is performace optimized.
What is tracing?Where it used.Explain few methods available
Tracing refers to collecting information about the application while it is running. You use tracing information to troubleshoot an application.
Tracing allows us to observe and correct programming errors. Tracing enables you to record information in various log files about the errors that might occur at run time. You can analyze these log files to find the cause of the errors.
In .NET we have objects called Trace Listeners. A listener is an object that receives the trace output and outputs it somewhere; that somewhere could be a window in your development environment, a file on your hard drive, a Windows Event log, a SQL Server or Oracle database, or any other customized data store.
The System.Diagnostics namespace provides the interfaces, classes, enumerations and structures that are used for tracing The System.Diagnostics namespace provides two classes named Trace and Debug that are used for writing errors and application execution information in logs.
All Trace Listeners have the following functions. Functionality of these functions is same except that the target media for the tracing output is determined by the Trace Listener.
Method Name
Result Fail Outputs the specified text with the Call Stack.
Write Outputs the specified text.
WriteLine Outputs the specified text and a carriage return.
Flush Flushes the output buffer to the target media.
Close Closes the output stream in order to not receive the tracing/debugging output.
What is the property available to check if the page posted or not?
The Page_Load event handler in the page checks for IsPostBack property value, to ascertain whether the page is posted. The Page.IsPostBack gets a value indicating whether the page is being loaded in response to the client postback, or it is for the first time. The value of Page.IsPostBack is True, if the page is being loaded in response to the client postback; while its value is False, when the page is loaded for the first time. The Page.IsPostBack property facilitates execution of certain routine in Page_Load, only once (for e.g. in Page load, we need to set default value in controls, when page is loaded for the first time. On post back, we check for true value for IsPostback value and then invoke server-side code to
update data).
Which are the abstract classes available under system.xml namespace?
The System.XML namespace provides XML related processing ability in .NET framework. XmlReader and XMLWriter are the two abstract classes at the core of .NET Framework XML classes:
1. XmlReader provides a fast, forward-only, read-only cursor for processing an XML document stream.
2. XmlWriter provides an interface for producing XML document streams that conform to the W3C's XML standards.
Both XmlReader and XmlWriter are abstract base classes, which define the functionality that all derived classes must support.
What are the derived classes from xmlReader and xmlWriter?
Both XmlReader and XmlWriter are abstract base classes, which define the functionality that all derived classes must support.
There are three concrete implementations of XmlReader:
1.XmlTextReader
2.XmlNodeReader
3.XmlValidatingReader
There are two concrete implementations of XmlWriter:
1.XmlTextWriter
2.XmlNodeWriter
XmlTextReader and XmlTextWriter support reading data to/from text-based stream, while XmlNodeReader and XmlNodeWriter are designed for working with in-memory DOM tree structure. The custom readers and writers can also be developed to extend the built-in functionality of XmlReader and XmlWriter.
What is managed and unmanaged code?
The .NET framework provides several core run-time services to the programs that run within it - for example exception handling and security. For these services to work, the code must provide a minimum level of information to the runtime. i.e., code executing under the control of the CLR is called managed code. For example, any code written in C# or Visual Basic .NET is managed code.
Code that runs outside the CLR is referred to as "unmanaged code." COM components, ActiveX components, and Win32 API functions are examples of unmanaged code.
Why do you need to serialize?
We need to serialize the object,if you want to pass object from one computer/application domain to another.Process of converting complex objects into stream of bytes that can be persisted or transported.Namespace for serialization is System.Runtime.Serialization.The ISerializable interface allows you to make any class Serializable..NET framework features 2 serializing method.
1.Binary Serialization 2.XML Serialization
Can a nested object be used in Serialization ?
Yes. If a class that is to be serialized contains references to objects of other classes, and if those classes have been marked as serializable, then their objects are serialized too.
Difference between int and int32 ?
Both are same. System.Int32 is a .NET class. Int is an alias name for System.Int32.
(A) With Respect to Program Access.
i) Private Assembly- It can be used only in one application.
ii) Public/Shared Assembly- It can be used by all applications in the server.
(B) With Respect to Number of Resources.
i) Static Assembly- It uses fixed resources.
ii) Dynamic Assembly- It supports dynamic creation of resouces or files at runtime programatically.
(C) With Respect to Deployment.
i) Satellite Assembly- Easily Deployable. (Visual Studio 2005).
ii) Resource-Only Assembly- In Visual Studio 2003.
(D) With Respect to Number of Assemblies.
i) Single File Assembly- /Bin/x.dll
ii) Multi File Assembly- /Bin/x.dll
y.dll
z.dll
---
->What are delegates?where are they used ?
A delegate defines a reference type that can be used to encapsulate a method with a specific signature. A delegate instance encapsulates a static or an instance method. Delegates are roughly similar to function pointers in C++; however, delegates are type-safe and secure.
When do you use virutal keyword?
When we need to override a method of the base class in the sub class, then we give the virtual keyword in the base class method. This makes the method in the base class to be overridable. Methods, properties, and indexers can be virtual, which means that their implementation can be overridden in derived classes.
When a virtual method is invoked, the run-time type of the object is checked for an overriding member. The overriding member in the most derived class is called, which might be the original member, if no derived class has overridden the member.
By default, methods are non-virtual. You cannot override a non-virtual method.
You cannot use the virtual modifier with the static, abstract, private or override modifiers.
Virtual properties behave like abstract methods, except for the differences in declaration and invocation syntax. It is an error to use the virtual modifier on a static property.A virtual inherited property can be overridden in a derived class by including a property declaration that uses the override modifier.
What Is Boxing And Unboxing?
Boxing :- Boxing is an implicit conversion of a value type to the type object type
Eg:-
Consider the following declaration of a value-type variable:
int i = 123;
object o = (object) i;
Boxing Conversion
UnBoxing :- Unboxing is an explicit conversion from the type object to a value type
Eg:
int i = 123; // A value type
object box = i; // Boxing
int j = (int)box; // Unboxing
What is Value type and refernce type in .Net?
Value Type : A variable of a value type always contains a value of that type. The assignment to a variable of a value type creates a copy of the assigned value, while the assignment to a variable of a reference type creates a copy of the reference but not of the referenced object.
The value types consist of two main categories:
* Stuct Type
* Enumeration Type
Reference Type :Variables of reference types, referred to as objects, store references to the actual data. This section introduces the following keywords used to declare reference types:
* Class
* Interface
* Delegate
This section also introduces the following built-in reference types:
* object
* string
What is the difference between structures and enumeration?
Unlike classes, structs are value types and do not require heap allocation. A variable of a struct type directly contains the data of the struct, whereas a variable of a class type contains a reference to the data. They are derived from System.ValueType class.
Enum->An enum type is a distinct type that declares a set of named constants.They are strongly typed constants. They are unique types that allow to declare symbolic names to integral values. Enums are value types, which means they contain their own value, can't inherit or be inherited from and assignment copies the value of one enum to another.
public enum Grade
{
A,
B,
C
}
What is namespaces?
Namespace is a logical naming scheme for group related types.Some class types that logically belong together they can be put into a common namespace. They prevent namespace collisions and they provide scoping. They are imported as "using" in C# or "Imports" in Visual Basic. It seems as if these directives specify a particular assembly, but they don't. A namespace can span multiple assemblies, and an assembly can define multiple namespaces. When the compiler needs the definition for a class type, it tracks through each of the different imported namespaces to the type name and searches each referenced assembly until it is found.
Namespaces can be nested. This is very similar to packages in Java as far as scoping is concerned.
What is global assembly cache?
Each computer where the common language runtime is installed has a machine-wide code cache called the global assembly cache. The global assembly cache stores assemblies specifically designated to be shared by several applications on the computer.
There are several ways to deploy an assembly into the global assembly cache:
· Use an installer designed to work with the global assembly cache. This is the preferred option for installing assemblies into the global assembly cache.
· Use a developer tool called the Global Assembly Cache tool (Gacutil.exe), provided by the .NET Framework SDK.
· Use Windows Explorer to drag assemblies into the cache.
What is MSIL?
When compiling to managed code, the compiler translates your source code into Microsoft intermediate language (MSIL), which is a CPU-independent set of instructions that can be efficiently converted to native code. MSIL includes instructions for loading, storing, initializing, and calling methods on objects, as well as instructions for arithmetic and logical operations, control flow, direct memory access, exception handling, and other operations. Before code can be run, MSIL must be converted to CPU-specific code, usually by a just-in-time (JIT) compiler. Because the common language runtime supplies one or more JIT compilers for each computer architecture it supports, the same set of MSIL can be JIT-compiled and run on any supported architecture.
When a compiler produces MSIL, it also produces metadata. Metadata describes the types in your code, including the definition of each type, the signatures of each type's members, the members that your code references, and other data that the runtime uses at execution time. The MSIL and metadata are contained in a portable executable (PE) file that is based on and extends the published Microsoft PE and common object file format (COFF) used historically for executable content. This file format, which accommodates MSIL or native code as well as metadata, enables the operating system to recognize common language runtime images. The presence of metadata in the file along with the MSIL enables your code to describe itself, which means that there is no need for type libraries or Interface Definition Language (IDL). The runtime locates and extracts the metadata from the file as needed during execution.
What is Jit compilers?.how many are available in clr?
Just-In-Time compiler- it converts the language that you write in .Net into machine language that a computer can understand. there are tqo types of JITs one is memory optimized & other is performace optimized.
What is tracing?Where it used.Explain few methods available
Tracing refers to collecting information about the application while it is running. You use tracing information to troubleshoot an application.
Tracing allows us to observe and correct programming errors. Tracing enables you to record information in various log files about the errors that might occur at run time. You can analyze these log files to find the cause of the errors.
In .NET we have objects called Trace Listeners. A listener is an object that receives the trace output and outputs it somewhere; that somewhere could be a window in your development environment, a file on your hard drive, a Windows Event log, a SQL Server or Oracle database, or any other customized data store.
The System.Diagnostics namespace provides the interfaces, classes, enumerations and structures that are used for tracing The System.Diagnostics namespace provides two classes named Trace and Debug that are used for writing errors and application execution information in logs.
All Trace Listeners have the following functions. Functionality of these functions is same except that the target media for the tracing output is determined by the Trace Listener.
Method Name
Result Fail Outputs the specified text with the Call Stack.
Write Outputs the specified text.
WriteLine Outputs the specified text and a carriage return.
Flush Flushes the output buffer to the target media.
Close Closes the output stream in order to not receive the tracing/debugging output.
What is the property available to check if the page posted or not?
The Page_Load event handler in the page checks for IsPostBack property value, to ascertain whether the page is posted. The Page.IsPostBack gets a value indicating whether the page is being loaded in response to the client postback, or it is for the first time. The value of Page.IsPostBack is True, if the page is being loaded in response to the client postback; while its value is False, when the page is loaded for the first time. The Page.IsPostBack property facilitates execution of certain routine in Page_Load, only once (for e.g. in Page load, we need to set default value in controls, when page is loaded for the first time. On post back, we check for true value for IsPostback value and then invoke server-side code to
update data).
Which are the abstract classes available under system.xml namespace?
The System.XML namespace provides XML related processing ability in .NET framework. XmlReader and XMLWriter are the two abstract classes at the core of .NET Framework XML classes:
1. XmlReader provides a fast, forward-only, read-only cursor for processing an XML document stream.
2. XmlWriter provides an interface for producing XML document streams that conform to the W3C's XML standards.
Both XmlReader and XmlWriter are abstract base classes, which define the functionality that all derived classes must support.
What are the derived classes from xmlReader and xmlWriter?
Both XmlReader and XmlWriter are abstract base classes, which define the functionality that all derived classes must support.
There are three concrete implementations of XmlReader:
1.XmlTextReader
2.XmlNodeReader
3.XmlValidatingReader
There are two concrete implementations of XmlWriter:
1.XmlTextWriter
2.XmlNodeWriter
XmlTextReader and XmlTextWriter support reading data to/from text-based stream, while XmlNodeReader and XmlNodeWriter are designed for working with in-memory DOM tree structure. The custom readers and writers can also be developed to extend the built-in functionality of XmlReader and XmlWriter.
What is managed and unmanaged code?
The .NET framework provides several core run-time services to the programs that run within it - for example exception handling and security. For these services to work, the code must provide a minimum level of information to the runtime. i.e., code executing under the control of the CLR is called managed code. For example, any code written in C# or Visual Basic .NET is managed code.
Code that runs outside the CLR is referred to as "unmanaged code." COM components, ActiveX components, and Win32 API functions are examples of unmanaged code.
Why do you need to serialize?
We need to serialize the object,if you want to pass object from one computer/application domain to another.Process of converting complex objects into stream of bytes that can be persisted or transported.Namespace for serialization is System.Runtime.Serialization.The ISerializable interface allows you to make any class Serializable..NET framework features 2 serializing method.
1.Binary Serialization 2.XML Serialization
Can a nested object be used in Serialization ?
Yes. If a class that is to be serialized contains references to objects of other classes, and if those classes have been marked as serializable, then their objects are serialized too.
Difference between int and int32 ?
Both are same. System.Int32 is a .NET class. Int is an alias name for System.Int32.
Saturday, June 26, 2010
.NET fundamentals 6
If a base class has a bunch of overloaded constructors, and an inherited class has another bunch of overloaded constructors, can you enforce a call from an inherited constructor to an arbitrary base constructor?
Yes, just place a colon, and then keyword base (parameter list to invoke the appropriate constructor) in the overloaded constructor definition inside the inherited class.
What's the difference between System.String and System.StringBuilder classes?
System.String is immutable, System.StringBuilder was designed with the purpose of having a mutable string where a variety of operations can be performed.
What is the difference between access specifier and access modifier?
Access specifiers: The access specifier determines how accessible the field is to code in other classes. Access ranges from totally accessible to totally inaccessible. You can optionally declare a field with an access specifier keyword: public, private, or protected.
Access Modifiers: You can optionally declare a field with a modifier keyword: final or volatile and/or static and/or transient.
Access specifier in C#?
1. Public: Any member declared public can be accessed from outside the class.
2. Private: it allows a class to hide its member variables and member functions from other class objects and function. Therefore, the private member of a class is not visible outside a class. if a member is declared private, only the functions of that class access the member.
3. Protected: This also allows a class to hide its member var. and member func. from other class objects and function, except the child class. it becomes important while implementing inheritance.
4. Internal: Internal member can be expose to other function and objects. it can be accessed from any class or method defined within the application in which the member is defined
5. Protected Internal: it's similar to Protected access specifier, it also allows a class to hide its member variables and member function to be accessed from other class objects and function, excepts child class, within the application. used while implementing inheritance.
What is a formatter?
A formatter is an object that is responsible for encoding and serializing data into messages on one end, and deserializing and decoding messages into data on the other end.
What is the use of JIT ?
JIT (Just - In - Time) is a compiler which converts MSIL code to Native Code (ie.. CPU-specific code that runs on the same computer architecture).Because the common language runtime supplies a JIT compiler for each supported CPU architecture, developers can write a set of MSIL that can be JIT-compiled and run on computers with different architectures. However, your managed code will run only on a specific operating system if it calls platform-specific native APIs, or a platform-specific class library.JIT compilation takes into account the fact that some code might never get called during execution. Rather than using time and memory to convert all the MSIL in a portable executable (PE) file to native code, it converts the MSIL as needed during execution and stores the resulting native code so that it is accessible for subsequent calls. The loader creates and attaches a stub to each of a type's methods when the type is loaded. On the initial call to the method, the stub passes control to the JIT compiler, which converts the MSIL for that method into native code and modifies the stub to direct execution to the location of the native code. Subsequent calls of the JIT-compiled method proceed directly to the native code that was previously generated, reducing the time it takes to JIT-compile and run the code.
What meant of assembly & global assembly cache (gac) & Meta data.
Assembly :-- An assembly is the primary building block of a .NET based application. It is a collection of functionality that is built, versioned, and deployed as a single implementation unit (as one or more files). All managed types and resources are marked either as accessible only within their implementation unit, or as accessible by code outside that unit. It overcomes the problem of 'dll Hell'.The .NET Framework uses assemblies as the fundamental unit for several purposes:
* Security
* Type Identity
* Reference Scope
* Versioning
* Deployment
Global Assembly Cache :-- Assemblies can be shared among multiple applications on the machine by registering them in global Assembly cache(GAC). GAC is a machine wide a local cache of assemblies maintained by the .NET Framework. We can register the assembly to global assembly cache by using gacutil command.
We can Navigate to the GAC directory, C:\winnt\Assembly in explore. In the tools menu select the cache properties; in the windows displayed you can set the memory limit in MB used by the GAC
MetaData :--Assemblies have Manifests. This Manifest contains Metadata information of the Module/Assembly as well as it contains detailed Metadata of other assemblies/modules references (exported). It's the Assembly Manifest which differentiates between an Assembly and a Module.
What is GUID , why we use it and where?
GUID :-- GUID is Short form of Globally Unique Identifier, a unique 128-bit number that is produced by the Windows OS or by some Windows applications to identify a particular component, application, file, database entry, and/or user. For instance, a Web site may generate a GUID and assign it to a user's browser to record and track the session. A GUID is also used in a Windows registry to identify COM DLLs. Knowing where to look in the registry and having the correct GUID yields a lot information about a COM object (i.e., information in the type library, its physical location, etc.). Windows also identifies user accounts by a username (computer/domain and username) and assigns it a GUID. Some database administrators even will use GUIDs as primary key values in databases.
GUIDs can be created in a number of ways, but usually they are a combination of a few unique settings based on specific point in time (e.g., an IP address, network MAC address, clock date/time, etc.).
Yes, just place a colon, and then keyword base (parameter list to invoke the appropriate constructor) in the overloaded constructor definition inside the inherited class.
What's the difference between System.String and System.StringBuilder classes?
System.String is immutable, System.StringBuilder was designed with the purpose of having a mutable string where a variety of operations can be performed.
What is the difference between access specifier and access modifier?
Access specifiers: The access specifier determines how accessible the field is to code in other classes. Access ranges from totally accessible to totally inaccessible. You can optionally declare a field with an access specifier keyword: public, private, or protected.
Access Modifiers: You can optionally declare a field with a modifier keyword: final or volatile and/or static and/or transient.
Access specifier in C#?
1. Public: Any member declared public can be accessed from outside the class.
2. Private: it allows a class to hide its member variables and member functions from other class objects and function. Therefore, the private member of a class is not visible outside a class. if a member is declared private, only the functions of that class access the member.
3. Protected: This also allows a class to hide its member var. and member func. from other class objects and function, except the child class. it becomes important while implementing inheritance.
4. Internal: Internal member can be expose to other function and objects. it can be accessed from any class or method defined within the application in which the member is defined
5. Protected Internal: it's similar to Protected access specifier, it also allows a class to hide its member variables and member function to be accessed from other class objects and function, excepts child class, within the application. used while implementing inheritance.
What is a formatter?
A formatter is an object that is responsible for encoding and serializing data into messages on one end, and deserializing and decoding messages into data on the other end.
What is the use of JIT ?
JIT (Just - In - Time) is a compiler which converts MSIL code to Native Code (ie.. CPU-specific code that runs on the same computer architecture).Because the common language runtime supplies a JIT compiler for each supported CPU architecture, developers can write a set of MSIL that can be JIT-compiled and run on computers with different architectures. However, your managed code will run only on a specific operating system if it calls platform-specific native APIs, or a platform-specific class library.JIT compilation takes into account the fact that some code might never get called during execution. Rather than using time and memory to convert all the MSIL in a portable executable (PE) file to native code, it converts the MSIL as needed during execution and stores the resulting native code so that it is accessible for subsequent calls. The loader creates and attaches a stub to each of a type's methods when the type is loaded. On the initial call to the method, the stub passes control to the JIT compiler, which converts the MSIL for that method into native code and modifies the stub to direct execution to the location of the native code. Subsequent calls of the JIT-compiled method proceed directly to the native code that was previously generated, reducing the time it takes to JIT-compile and run the code.
What meant of assembly & global assembly cache (gac) & Meta data.
Assembly :-- An assembly is the primary building block of a .NET based application. It is a collection of functionality that is built, versioned, and deployed as a single implementation unit (as one or more files). All managed types and resources are marked either as accessible only within their implementation unit, or as accessible by code outside that unit. It overcomes the problem of 'dll Hell'.The .NET Framework uses assemblies as the fundamental unit for several purposes:
* Security
* Type Identity
* Reference Scope
* Versioning
* Deployment
Global Assembly Cache :-- Assemblies can be shared among multiple applications on the machine by registering them in global Assembly cache(GAC). GAC is a machine wide a local cache of assemblies maintained by the .NET Framework. We can register the assembly to global assembly cache by using gacutil command.
We can Navigate to the GAC directory, C:\winnt\Assembly in explore. In the tools menu select the cache properties; in the windows displayed you can set the memory limit in MB used by the GAC
MetaData :--Assemblies have Manifests. This Manifest contains Metadata information of the Module/Assembly as well as it contains detailed Metadata of other assemblies/modules references (exported). It's the Assembly Manifest which differentiates between an Assembly and a Module.
What is GUID , why we use it and where?
GUID :-- GUID is Short form of Globally Unique Identifier, a unique 128-bit number that is produced by the Windows OS or by some Windows applications to identify a particular component, application, file, database entry, and/or user. For instance, a Web site may generate a GUID and assign it to a user's browser to record and track the session. A GUID is also used in a Windows registry to identify COM DLLs. Knowing where to look in the registry and having the correct GUID yields a lot information about a COM object (i.e., information in the type library, its physical location, etc.). Windows also identifies user accounts by a username (computer/domain and username) and assigns it a GUID. Some database administrators even will use GUIDs as primary key values in databases.
GUIDs can be created in a number of ways, but usually they are a combination of a few unique settings based on specific point in time (e.g., an IP address, network MAC address, clock date/time, etc.).
Subscribe to:
Posts (Atom)